Deutsch-Jozsa 알고리즘
Deutsch의 알고리즘은 쿼리 문제에서 모든 고전 알고리즘을 능가하지만, 그 이점은 상당히 제한적입니다: 쿼리 1회 대 2회입니다. Deutsch-Jozsa 알고리즘은 이 이점을 확장하며, 실제로 몇 가지 서로 다른 쿼리 문제를 해결하는 데 사용할 수 있습니다.
다음은 Deutsch-Jozsa 알고리즘의 양자 Circuit 설명입니다. 그림에는 나와 있지 않지만, 해결하려는 특정 문제에 따라 추가적인 고전 후처리 단계가 필요할 수도 있습니다.

물론, 이 알고리즘이 실제로 어떤 문제를 해결하는지는 아직 다루지 않았습니다. 이는 이어지는 두 절에서 설명합니다.
Deutsch-Jozsa 문제
Deutsch-Jozsa 알고리즘이 원래 해결하도록 설계된 쿼리 문제인 Deutsch-Jozsa 문제부터 시작하겠습니다.
이 문제의 입력 함수는 임의의 양의 정수 에 대해 형태를 취합니다. Deutsch의 문제와 마찬가지로, 과제는 가 상수 함수이면 을, 가 균형 함수이면 을 출력하는 것입니다. 여기서 균형이란 함수가 을 취하는 입력 문자열의 수와 함수가 을 취하는 입력 문자열의 수가 같다는 의미입니다.
이 보다 클 때, 형태의 함수 중 상수도 균형도 아닌 함수가 존재한다는 점에 주목하세요. 예를 들어, 다음과 같이 정의된 함수 는
이 두 범주 중 어디에도 속하지 않습니다. Deutsch-Jozsa 문제에서는 이런 함수는 단순히 고려하지 않습니다 — 이들은 "신경 쓰지 않는" 입력으로 취급됩니다. 즉, 이 문제에서는 가 상수 함수이거나 균형 함수라는 약속이 주어집니다.
Deutsch-Jozsa 알고리즘은 단 하나의 쿼리로 이 문제를 다음과 같은 방식으로 해결합니다: 개의 측정 결과가 모두 이면 함수 는 상수 함수이고, 그렇지 않아서 측정 결과 중 하나 이상이 이면 함수 는 균형 함수입니다. 다른 방법으로 표현하면, 위에서 설명한 Circuit 이후에 측정 결과들의 OR를 계산하여 출력을 생성하는 고전 후처리 단계가 뒤따릅니다.
알고리즘 분석
Deutsch-Jozsa 문제에 대한 Deutsch-Jozsa 알고리즘의 성능을 분석하려면, 먼저 Hadamard Gate 한 층의 작용에 대해 생각해 보는 것이 도움이 됩니다. Hadamard 연산은 일반적인 방식으로 행렬로 표현할 수 있습니다.
그러나 표준 기저 상태에 대한 작용으로도 이 연산을 표현할 수 있습니다:
이 두 식을 하나의 공식으로 결합하면,
이는 의 두 가지 선택 모두에 대해 성립합니다.
이제 단일 qubit 대신 개의 Qubit이 있고, 각 Qubit에 Hadamard 연산이 수행된다고 가정해 보겠습니다. 개의 Qubit에 대한 결합 연산은 텐서 곱 (번)로 설명되며, 간결하고 명확하게 으로 표기합니다. 위의 공식을 사용하여 전개한 후 단순화하면, 개의 Qubit의 표준 기저 상태에 대한 이 결합 연산의 작용을 다음과 같이 표현할 수 있습니다:
여기서, Qiskit의 인덱싱 관례에 따라 길이 의 이진 문자열을 및 으로 표기하고 있습니다.
이 공식은 위의 양자 Circuit을 분석하는 데 유용한 도구를 제공합니다. 첫 번째 Hadamard Gate 층이 수행된 후, 개의 qubit(나머지와 별도로 처리되는 가장 왼쪽/아래쪽 qubit 포함)의 상태는 다음과 같습니다.
연산이 수행되면, 이 상태는 다음과 같이 변환됩니다.
이는 Deutsch의 알고리즘 분석에서 보았던 것과 완전히 동일한 위상 킥백 현상을 통해 이루어집니다.
그런 다음 두 번째 Hadamard Gate 층이 수행되며, (위의 공식에 의해) 이 상태를 다음과 같이 변환합니다.
이 표현은 다소 복잡해 보이며, 함수 에 대해 더 많은 것을 알지 않고는 서로 다른 측정 결과를 얻을 확률에 대해 많은 것을 결론 내릴 수 없습니다.
다행히도, 우리가 알아야 할 것은 모든 측정 결과가 일 확률뿐입니다 — 왜냐하면 그것이 알고리즘이 를 상수로 판정할 확률이기 때문입니다. 이 확률은 간단한 공식으로 표현됩니다.
더 자세히 설명하면, 가 상수 함수인 경우 모든 문자열 에 대해 이면 합의 값은 이고, 모든 문자열 에 대해 이면 합의 값은 입니다. 으로 나누고 절댓값의 제곱을 취하면 이 됩니다.
반면에 가 균형 함수인 경우, 는 절반의 문자열 에서 을, 나머지 절반에서 을 취하므로, 합에서 항과 항이 상쇄되어 값은 이 됩니다.
따라서 약속이 이행될 때 알고리즘이 올바르게 동작한다는 결론을 내릴 수 있습니다.
고전적 어려움
Deutsch-Jozsa 알고리즘은 매번 올바르게 작동하여 약속이 충족될 때 항상 정확한 답을 제공하며, 단 하나의 쿼리만 필요합니다. Deutsch-Jozsa 문제에 대한 고전 쿼리 알고리즘과 비교하면 어떨까요?
먼저, Deutsch-Jozsa 문제를 올바르게 해결하는 결정론적 고전 알고리즘은 지수적으로 많은 쿼리를 수행해야 합니다: 최악의 경우 번의 쿼리가 필요합니다. 그 이유는, 결정론적 알고리즘이 개 이하의 서로 다른 문자열에 대해 를 쿼리하고 매번 같은 함수 값을 얻는다면, 두 가지 답이 모두 여전히 가능하기 때문입니다. 함수가 상수일 수도 있고, 또는 균형 함수이지만 불운하게도 쿼리가 모두 같은 함수 값을 반환하는 경우일 수도 있습니다.
두 번째 가능성은 있을 것 같지 않아 보일 수 있지만 — 결정론적 알고리즘에는 무작위성이나 불확실성이 없으므로, 특정 함수에 대해 체계적으로 실패할 것입니다. 따라서 이 점에서 양자 알고리즘은 고전 알고리즘에 비해 상당한 이점을 가집니다.
그러나 한 가지 주의할 점이 있는데, 확률론적 고전 알고리즘은 단 몇 번의 쿼리만으로 매우 높은 확률로 Deutsch-Jozsa 문제를 해결할 수 있다는 것입니다. 특히, 길이 의 서로 다른 문자열 몇 개를 무작위로 선택하여 그 문자열들에 대해 를 쿼리하면, 가 균형 함수일 때 모든 쿼리에서 같은 함수 값을 얻을 가능성은 낮습니다.
구체적으로, 개의 입력 문자열 을 균등 무작위로 선택하여 를 평가하고, 함수 값이 모두 같으면 , 그렇지 않으면 로 답하면, 가 상수 함수일 때는 항상 정확하고, 가 균형 함수일 때 오답을 낼 확률은 에 불과합니다. 예를 들어 로 설정하면, 이 알고리즘은 % 이상의 확률로 정확하게 답합니다.
이러한 이유로, 양자 알고리즘의 고전 알고리즘에 대한 이점은 여전히 상당히 제한적이지만 — 그럼에도 불구하고 이는 정량화 가능한 이점으로 Deutsch의 알고리즘에 비해 개선된 것입니다.
Qiskit으로 구현하는 Deutsch-Jozsa
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-aer
from qiskit import QuantumCircuit
from qiskit_aer import AerSimulator
import numpy as np
Qiskit에서 Deutsch-Jozsa 알고리즘을 구현하려면, 먼저 dj_query 함수를 정의합니다. 이 함수는 Deutsch-Jozsa 문제의 약속 조건을 만족하는 함수를 무작위로 선택하여 해당 Query Gate를 구현하는 양자 Circuit을 생성합니다.
50% 확률로 함수는 상수(constant)이고, 나머지 50% 확률로 균형(balanced) 함수입니다.
각 경우에 대해 해당 유형의 함수 중에서 균등하게 선택합니다.
인수는 함수의 입력 비트 수입니다.
def dj_query(num_qubits):
# Create a circuit implementing for a query gate for a random function
# satisfying the promise for the Deutsch-Jozsa problem.
qc = QuantumCircuit(num_qubits + 1)
if np.random.randint(0, 2):
# Flip output qubit with 50% chance
qc.x(num_qubits)
if np.random.randint(0, 2):
# return constant circuit with 50% chance
return qc
# Choose half the possible input strings
on_states = np.random.choice(
range(2**num_qubits), # numbers to sample from
2**num_qubits // 2, # number of samples
replace=False, # makes sure states are only sampled once
)
def add_cx(qc, bit_string):
for qubit, bit in enumerate(reversed(bit_string)):
if bit == "1":
qc.x(qubit)
return qc
for state in on_states:
qc.barrier() # Barriers are added to help visualize how the functions are created.
qc = add_cx(qc, f"{state:0b}")
qc.mcx(list(range(num_qubits)), num_qubits)
qc = add_cx(qc, f"{state:0b}")
qc.barrier()
return qc
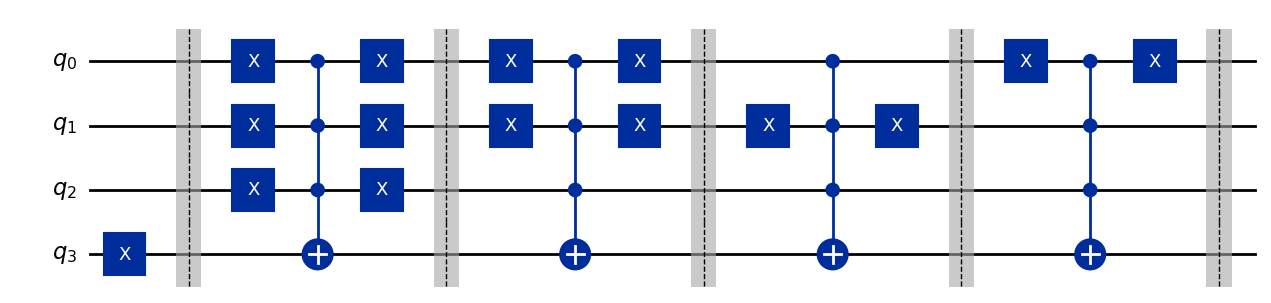
draw 메서드를 사용하여 Query Gate의 양자 Circuit 구현을 확인할 수 있습니다.
display(dj_query(3).draw(output="mpl"))

다음으로, Query Gate의 양자 Circuit 구현을 인수로 받아 Deutsch-Jozsa Circuit을 생성하는 함수를 정의합니다.
def compile_circuit(function: QuantumCircuit):
# Compiles a circuit for use in the Deutsch-Jozsa algorithm.
n = function.num_qubits - 1
qc = QuantumCircuit(n + 1, n)
qc.x(n)
qc.h(range(n + 1))
qc.compose(function, inplace=True)
qc.h(range(n))
qc.measure(range(n), range(n))
return qc
마지막으로, Deutsch-Jozsa Circuit을 한 번 실행하는 함수를 정의합니다.
def dj_algorithm(function: QuantumCircuit):
# Determine if a function is constant or balanced.
qc = compile_circuit(function)
result = AerSimulator().run(qc, shots=1, memory=True).result()
measurements = result.get_memory()
if "1" in measurements[0]:
return "balanced"
return "constant"
함수를 무작위로 선택하고, 해당 함수에 대한 Query Gate의 양자 Circuit 구현을 출력한 다음, 그 함수에 대해 Deutsch-Jozsa 알고리즘을 실행하여 구현을 테스트할 수 있습니다.
f = dj_query(3)
display(f.draw("mpl"))
display(dj_algorithm(f))
'balanced'
Bernstein-Vazirani 문제
다음으로 Bernstein-Vazirani 문제라고 알려진 문제를 살펴보겠습니다. 이 문제는 푸리에 샘플링 문제라고도 불리는데, 같은 이름으로 불리는 더 일반적인 형식의 문제도 존재합니다.
먼저 몇 가지 표기법을 소개하겠습니다. 길이가 인 임의의 두 이진 문자열 과 에 대해 다음과 같이 정의합니다.
이 연산을 *이진 내적(binary dot product)*이라고 부르겠습니다. 다음과 같이 대안적으로 정의할 수도 있습니다.
이 연산은 대칭적인 연산으로, 와 를 서로 바꾸어도 결과가 변하지 않으므로 편의에 따라 자유롭게 바꿀 수 있습니다. 이진 내적 를 문자열 에서 인 위치에 해당하는 의 비트들의 패리티로 생각하면 유용할 때가 있습니다. 반대로, 문자열 에서 인 위치에 해당하는 의 비트들의 패리티로 생각할 수도 있습니다.
이 표기법을 이용하여 이제 Bernstein-Vazirani 문제를 정의할 수 있습니다.
이 문제를 위해 새로운 양자 알고리즘이 필요하지 않습니다. Deutsch-Jozsa 알고리즘이 이를 해결합니다. 명확성을 위해, OR 계산이라는 고전적 후처리 단계를 포함하지 않는 위의 양자 Circuit을 Deutsch-Jozsa Circuit이라고 부르겠습니다.
알고리즘 분석
Bernstein-Vazirani 문제의 약속을 만족하는 함수에 대해 Deutsch-Jozsa Circuit이 어떻게 작동하는지 분석하기 위해, 먼저 간단한 관찰부터 시작하겠습니다. 이진 내적을 이용하면, 개의 Hadamard Gate가 개의 Qubit의 표준 기저 상태에 미치는 작용을 다음과 같이 나타낼 수 있습니다.
Deutsch 알고리즘 분석에서 보았던 것과 유사하게, 이는 임의의 정수 에 대해 의 값이 가 짝수인지 홀수인지에만 달려 있기 때문입니다.
Deutsch–Jozsa Circuit으로 돌아오면, 첫 번째 Hadamard Gate 층이 수행된 후 개의 Qubit의 상태는 다음과 같습니다.
이어서 쿼리 Gate가 수행되면, (위상 킥백 현상을 통해) 상태가 다음과 같이 변환됩니다.
Hadamard Gate 층의 작용에 대한 공식을 이용하면, 두 번째 Hadamard Gate 층이 이 상태를 다음과 같이 변환함을 알 수 있습니다.
이제 합 안의 의 지수 부분에서 몇 가지 단순화를 할 수 있습니다. 어떤 문자열 에 대해 임이 약속되어 있으므로, 상태를 다음과 같이 표현할 수 있습니다.
와 는 이진 값이므로, 덧셈을 배타적 OR로 대체할 수 있습니다. 이는 의 지수에서 정수에 있어 중요한 것은 짝수인지 홀수인지뿐이기 때문입니다. 이진 내적의 대칭성을 이용하면, 다음과 같이 상태를 표현할 수 있습니다.
(이진 내적이 배타적 OR보다 높은 우선순위를 갖는 것이 관례이므로 괄호가 엄밀히 필요하지는 않지만, 명확성을 위해 추가했습니다.)
이 시점에서 다음 공식을 활용합니다.
이 공식은 비트에 대한 유사한 공식으로부터 유도할 수 있습니다.
그리고 이진 내적과 비트별 배타적 OR의 전개를 통해 다음과 같이 보일 수 있습니다.
이를 통해 측정 직전의 Circuit 상태를 다음과 같이 표현할 수 있습니다.
마지막 단계는 모든 이진 문자열 에 대해 성립하는 또 다른 공식을 활용하는 것입니다.
여기서 앞으로 이 강의에서 여러 번 사용할 간단한 문자열 표기법을 사용합니다. 은 길이 의 모두 인 문자열을 의미합니다.
이 공식이 성립함을 보이는 간단한 방법은 두 경우를 따로 살펴보는 것입니다. 이면 모든 문자열 에 대해 이므로, 합의 각 항의 값은 이고 합산 후 으로 나누면 을 얻습니다. 반면에 의 어느 한 비트라도 이면, 이진 내적 는 의 가능한 선택 중 정확히 절반에 대해 이고 나머지 절반에 대해 입니다. 이는 에서 인 위치의 의 비트를 뒤집으면 이진 내적 의 값이 (에서 로, 또는 에서 으로) 뒤집히기 때문입니다.
이 공식을 측정 전 Circuit 상태의 단순화에 적용하면 다음을 얻습니다.
이는 이 일 때만 성립하기 때문입니다. 따라서 측정 결과가 우리가 찾고자 하는 문자열 를 정확히 드러냅니다.
고전적 어려움
Deutsch-Jozsa Circuit은 단 하나의 쿼리로 Bernstein-Vazirani 문제를 해결하지만, 어떠한 고전적 쿼리 알고리즘도 이 문제를 해결하려면 최소 번의 쿼리가 필요합니다.
이는 이 경우 매우 단순한 이른바 정보 이론적 논증으로 추론할 수 있습니다. 각 고전적 쿼리는 해답에 대한 단 하나의 비트 정보를 드러내며, 밝혀야 할 정보는 비트이므로 최소 번의 쿼리가 필요합니다.
실제로 Bernstein-Vazirani 문제는 각 가능한 위치에 하나의 이 있고 나머지 비트가 모두 인 개의 문자열 각각에 대해 함수를 쿼리하면 고전적으로 해결할 수 있으며, 이를 통해 의 비트를 하나씩 알아낼 수 있습니다. 따라서 이 문제에서 양자 알고리즘과 고전 알고리즘의 차이는 번의 쿼리 대 번의 쿼리입니다.
Qiskit으로 Bernstein-Vazirani 구현하기
위에서 이미 Deutsch-Jozsa Circuit을 구현했으며, 여기서는 이를 활용하여 Bernstein-Vazirani 문제를 풀겠습니다. 먼저 임의의 이진 문자열 가 주어졌을 때 Bernstein-Vazirani 문제의 쿼리 Gate를 구현하는 함수를 정의합니다.
def bv_query(s):
# Create a quantum circuit implementing a query gate for the
# Bernstein-Vazirani problem.
qc = QuantumCircuit(len(s) + 1)
for index, bit in enumerate(reversed(s)):
if bit == "1":
qc.cx(index, len(s))
return qc
display(bv_query("1011").draw(output="mpl"))

이제 앞서 정의한 compile_circuit 함수를 사용하여 함수에 대해 Deutsch-Jozsa Circuit을 실행하는 함수를 만들 수 있습니다.
def bv_algorithm(function: QuantumCircuit):
qc = compile_circuit(function)
result = AerSimulator().run(qc, shots=1, memory=True).result()
return result.get_memory()[0]
display(bv_algorithm(bv_query("1011")))
'1011'
명칭에 관한 참고사항
Bernstein-Vazirani 문제의 맥락에서는 Deutsch-Jozsa 알고리즘을 "Bernstein-Vazirani 알고리즘"이라고 부르는 경우가 흔합니다. 이는 약간 오해를 불러일으킬 수 있는데, 이 알고리즘은 실제로 Deutsch-Jozsa 알고리즘 자체로서, Bernstein과 Vazirani 자신도 자신들의 연구에서 이 점을 명확히 밝혔습니다.
Bernstein과 Vazirani가 한 것은 Deutsch-Jozsa 알고리즘이 (위에서 기술된 형태의) Bernstein-Vazirani 문제를 해결함을 보인 후, 재귀적 푸리에 샘플링 문제라고 알려진 훨씬 복잡한 문제를 정의한 것입니다. 이 문제는 트리 형태로 구성된 문제의 서로 다른 인스턴스들에 대한 해답이 새로운 수준의 문제를 여는 구조를 가진 매우 인위적인 문제입니다. Bernstein-Vazirani 문제는 본질적으로 이 더 복잡한 문제의 기저 케이스에 해당합니다.
재귀적 푸리에 샘플링 문제는 양자 알고리즘이 확률적 알고리즘에 비해 이른바 초다항식(super-polynomial) 우위를 갖는 것으로 알려진 최초의 쿼리 문제 사례였으며, Deutsch-Jozsa 알고리즘이 제공하는 양자 대 고전의 우위를 뛰어넘습니다. 직관적으로 말하면, 재귀적 버전의 문제는 양자 알고리즘의 대 이라는 우위를 훨씬 큰 규모로 증폭시킵니다.
이 우위를 입증하는 수학적 분석에서 가장 어려운 부분은 고전적 쿼리 알고리즘이 많은 쿼리 없이는 문제를 해결할 수 없음을 보이는 것입니다. 이는 매우 전형적인 현상으로, 많은 문제에서 창의적인 고전적 접근법이 효율적으로 문제를 해결하지 못함을 배제하는 것은 상당히 어려울 수 있습니다.
Simon의 문제와 다음 절에서 설명하는 그에 대한 알고리즘은 훨씬 더 단순한 초다항식(실제로는 지수적) 양자 대 고전 우위의 예시를 제공하며, 이러한 이유로 재귀적 푸리에 샘플링 문제는 덜 자주 논의됩니다. 그럼에도 불구하고, 그것 자체로 흥미로운 계산 문제임에는 틀림없습니다.