Grover 알고리즘
이 Qiskit in Classrooms 모듈을 사용하려면, 학생들의 Python 환경에 다음 패키지가 설치되어 있어야 합니다:
qiskitv2.1.0 이상qiskit-ibm-runtimev0.40.1 이상qiskit-aerv0.17.0 이상qiskit.visualizationnumpypylatexenc
위 패키지의 설치 및 설정 방법은 Qiskit 설치 가이드를 참고하세요. 실제 양자 컴퓨터에서 작업을 실행하려면, IBM Cloud 계정 설정 가이드의 절차에 따라 IBM Quantum® 계정을 만들어야 합니다.
이 모듈은 테스트 결과 12초의 QPU 시간을 사용했습니다. 이는 추정치이며, 실제 사용량은 다를 수 있습니다.
# Added by doQumentation — required packages for this notebook
!pip install -q qiskit qiskit-ibm-runtime
# Uncomment and modify this line as needed to install dependencies
#!pip install 'qiskit>=2.1.0' 'qiskit-ibm-runtime>=0.40.1' 'qiskit-aer>=0.17.0' 'numpy' 'pylatexenc'
소개
Grover 알고리즘은 비구조적 탐색 문제를 다루는 기초적인 양자 알고리즘입니다. 비구조적 탐색 문제란, 개의 항목과 특정 항목이 원하는 것인지 확인하는 방법이 주어졌을 때, 원하는 항목을 얼마나 빠르게 찾을 수 있는지에 관한 문제입니다. 고전적인 컴퓨팅에서는 데이터가 정렬되어 있지 않고 활용할 구조도 없다면, 각 항목을 하나씩 확인하는 것이 최선입니다. 이 경우 쿼리 복잡도는 이며, 평균적으로 목표 항목을 찾기 전에 약 절반의 항목을 확인해야 합니다.
1996년 Lov Grover가 발표한 Grover 알고리즘은 양자 컴퓨터가 이 문제를 훨씬 효율적으로 해결할 수 있음을 보여줍니다. 표시된 항목을 높은 확률로 찾는 데 단계만 필요합니다. 이는 고전적인 방법에 비해 *이차적 속도 향상(quadratic speedup)*을 나타내며, 대규모 데이터셋에서 특히 의미 있습니다.
이 알고리즘은 다음과 같은 맥락에서 작동합니다:
- 문제 설정: 함수 가 있으며, 가 원하는 항목이면 1을, 그렇지 않으면 0을 반환합니다. 이 함수는 를 쿼리해야만 데이터에 대해 알 수 있기 때문에 오라클(oracle) 또는 *블랙박스(black box)*라고도 합니다.
- 양자의 유용성: 이 문제에 대한 고전적인 알고리즘은 평균적으로 번의 쿼리가 필요하지만, Grover 알고리즘은 약 번의 쿼리로 해를 찾을 수 있습니다. 큰 에서 이는 훨씬 빠릅니다.
- 작동 원리 (개략적 설명):
- 양자 컴퓨터는 먼저 모든 가능한 상태의 *중첩(superposition)*을 생성하여, 모든 가능한 항목을 동시에 표현합니다.
- 그런 다음 올바른 답의 확률을 증폭시키고 나머지를 줄이는 양자 연산 시퀀스(Grover 반복)를 반복적으로 적용합니다.
- 충분한 반복 후, 양자 상태를 측정하면 높은 확률로 올바른 답을 얻을 수 있습니다.
아래는 Grover 알고리즘의 기본적인 다이어그램으로, 많은 세부 사항을 생략한 것입니다. 더 자세한 다이어그램은 이 논문을 참고하세요.
Grover 알고리즘에 대해 몇 가지 주목할 사항이 있습니다:
- 비구조적 탐색에서 최적입니다. 어떤 양자 알고리즘도 보다 적은 쿼리로 이 문제를 풀 수 없습니다.
- 일부 다른 양자 알고리즘(예: 소인수분해를 위한 Shor 알고리즘)과 달리, 지수적이 아닌 이차적 속도 향상만 제공합니다.
- 암호 시스템에 대한 무차별 대입 공격의 속도를 높이는 등 실용적인 함의가 있지만, 이 속도 향상만으로는 대부분의 현대 암호화를 단독으로 깨기에 충분하지 않습니다.
기본적인 컴퓨팅 개념과 쿼리 모델에 익숙한 학부생에게 Grover 알고리즘은 양자 컴퓨팅이 특정 문제에서 고전적인 접근법을 능가할 수 있음을 명확하게 보여주는 사례입니다. 설령 그 향상이 "단지" 이차적이더라도 말입니다. 또한 더 고급 양자 알고리즘과 양자 컴퓨팅의 광범위한 잠재력을 이해하는 관문 역할도 합니다.
진폭 증폭(Amplitude amplification)은 몇몇 고전적인 알고리즘에 비해 이차적 속도 향상을 얻는 데 사용할 수 있는 범용 양자 알고리즘 또는 서브루틴입니다. Grover 알고리즘은 비구조적 탐색 문제에서 이 속도 향상을 최초로 증명한 알고리즘입니다. Grover 탐색 문제를 공식화하려면, 하나 이상의 계산 기저 상태를 찾고자 하는 상태로 표시하는 오라클 함수와, 표시된 상태의 진폭을 증가시켜 나머지 상태를 억제하는 증폭 Circuit이 필요합니다.
여기서는 Grover 오라클을 구성하는 방법과, Qiskit Circuit 라이브러리의 GroverOperator를 사용하여 Grover 탐색 인스턴스를 손쉽게 설정하는 방법을 설명합니다. 런타임 Sampler 프리미티브를 사용하면 Grover Circuit을 원활하게 실행할 수 있습니다.
이론
이진 문자열을 단일 이진 변수에 매핑하는 함수 가 존재한다고 가정합니다. 즉,
위에서 정의된 한 예시는 다음과 같습니다.
위에서 정의된 또 다른 예시는 다음과 같습니다.
1에 매핑되는 의 인수 에 해당하는 양자 상태를 찾는 것이 과제입니다. 즉, 이 되는 모든 을 찾는 것입니다(해가 없다면 그 사실을 보고합니다). 해가 아닌 것은 로 표기합니다. 물론 이 작업은 양자 컴퓨터에서 양자 상태를 사용하여 수행하므로, 이진 문자열을 상태로 표현하는 것이 유용합니다:
양자 상태(Dirac) 표기법을 사용하면, 개의 Qubit에서 개의 가능한 상태 중 하나 이상의 특별한 상태 를 찾는 것이며, 해가 아닌 것은 로 표기합니다.
함수 는 오라클로 제공된다고 생각할 수 있습니다. 오라클은 상태 에 대한 효과를 쿼리하여 결정할 수 있는 블랙박스입니다. 실제로는 함수를 알고 있는 경우가 많지만, 구현이 매우 복잡할 수 있어서 의 쿼리 또는 적용 횟수를 줄이는 것이 중요할 수 있습니다. 또는 한 사람이 다른 사람이 제어하는 오라클을 쿼리하는 패러다임을 상상해볼 수 있습니다. 이 경우 오라클 함수를 알 수 없고, 쿼리를 통해 특정 상태에 대한 동작만 알 수 있습니다.
이것은 "비구조적" 탐색 문제입니다. 에는 탐색을 돕는 특별한 구조가 없습니다. 출력이 정렬되어 있지 않고 해가 군집을 이루는 것도 아닙니다. 유추하자면, 오래된 종이 전화번호부를 생각해보세요. 이 비구조적 탐색은 특정 __번호__를 찾기 위해 전화번호부를 훑는 것과 같습니다. 알파벳순으로 정렬된 이름 목록을 검색하는 것과는 다릅니다.
단일 해를 찾는 경우, 고전적으로는 에 선형인 횟수의 쿼리가 필요합니다. 운이 좋으면 첫 번째 시도에 해를 찾을 수도 있지만, 처음 번의 시도에서 해를 못 찾으면 번째 입력을 쿼리해야 해가 있는지 알 수 있습니다. 함수에 활용할 수 있는 구조가 없으므로, 평균적으로 번의 시도가 필요합니다. Grover 알고리즘은 에 비례하는 횟수의 쿼리 또는 계산이 필요합니다.
Grover 알고리즘의 Circuit 개요
Grover 알고리즘의 완전한 수학적 설명은 IBM Quantum Learning에서 John Watrous가 진행한 강좌인 양자 알고리즘의 기초에서 찾을 수 있습니다. 간략한 내용은 이 모듈 끝 부록에 제공됩니다. 여기서는 Grover 알고리즘을 구현하는 양자 Circuit의 전반적인 구조만 살펴봅니다.
Grover 알고리즘은 다음 단계로 나눌 수 있습니다:
- 초기 중첩 준비 (모든 Qubit에 Hadamard Gate 적용)
- 목표 상태를 위상 반전으로 "표시"
- 모든 Qubit에 Hadamard Gate와 위상 반전을 적용하는 "확산(diffusion)" 단계
- 목표 상태를 측정할 확률을 최대화하기 위한 표시 및 확산 단계의 반복
- 측정
 표시 Gate 와 로 구성된 확산 레이어를 통틀어 "Grover 연산자"라고 부릅니다. 이 다이어그램에서는 Grover 연산자가 한 번만 반복됩니다.
표시 Gate 와 로 구성된 확산 레이어를 통틀어 "Grover 연산자"라고 부릅니다. 이 다이어그램에서는 Grover 연산자가 한 번만 반복됩니다.
Hadamard Gate 는 양자 컴퓨팅 전반에서 널리 사용되는 잘 알려진 Gate입니다. Hadamard Gate는 중첩 상태를 만들며, 구체적으로 다음과 같이 정의됩니다:
다른 상태에 대한 동작은 선형성을 통해 정의됩니다. 특히, Hadamard Gate 레이어를 통해 모든 Qubit이 인 초기 상태(로 표기)에서 각 Qubit이 또는 로 측정될 확률을 가지는 상태로 이동할 수 있습니다. 이는 고전 컴퓨팅과는 다른 방식으로 모든 가능한 상태의 공간을 탐색할 수 있게 해줍니다.
Hadamard Gate의 중요한 부수 성질은, 두 번째 적용 시 이러한 중첩 상태를 되돌릴 수 있다는 것입니다:
이 성질은 바로 다음에서 중요하게 사용됩니다.
이해도 확인
아래 질문을 읽고, 답을 생각해본 후 삼각형을 클릭하여 해답을 확인하세요.
Hadamard Gate의 정의에서 시작하여, 두 번째 Hadamard Gate 적용이 위에서 주장한 대로 중첩 상태를 되돌림을 증명하세요.
답:
상태에 X를 적용하면 +1이 나오고, 상태에 X를 적용하면 -1이 나옵니다. 따라서 50-50 분포라면 기댓값은 0이 됩니다.
Gate는 덜 일반적이며, 다음과 같이 정의됩니다:
마지막으로, Gate는 다음과 같이 정의됩니다:
이 정의의 효과는, 가 인 목표 상태의 부호를 반전시키고 다른 상태는 그대로 둔다는 것입니다.
매우 추상적인 수준에서 Circuit의 각 단계는 다음과 같이 이해할 수 있습니다:
- 첫 번째 Hadamard 레이어: Qubit을 모든 가능한 상태의 중첩에 놓습니다.
- : 목표 상태 앞에 "-" 부호를 추가하여 표시합니다. 이것은 즉시 측정 확률을 변경하지는 않지만, 이후 단계에서 목표 상태가 어떻게 동작할지를 바꿉니다.
- 또 다른 Hadamard 레이어: 이전 단계에서 도입된 "-" 부호가 일부 항들 사이의 상대적 부호를 변경합니다. Hadamard Gate는 계산 기저 상태의 혼합인 를 하나의 계산 기저 상태 으로, 를 로 변환하므로, 이 상대적 부호 차이가 이제 측정되는 상태에 영향을 주기 시작합니다.
- 마지막 Hadamard Gate 레이어가 적용된 후 측정이 이루어집니다. 다음 섹션에서 이것이 어떻게 작동하는지 더 자세히 살펴봅니다.
예시
Grover 알고리즘의 작동 방식을 더 잘 이해하기 위해, 2개의 Qubit으로 이루어진 작은 예시를 다루어 보겠습니다. 양자역학과 Dirac 표기법에 집중하지 않는 분들에게는 선택 사항입니다. 그러나 양자 컴퓨터를 실질적으로 다루고자 하는 분들에게는 적극 권장합니다.
아래는 양자 상태가 여러 위치에 표기된 Circuit 다이어그램입니다. 2개의 Qubit만 있으므로, 어떤 경우에도 측정 가능한 상태는 , , , 의 네 가지뿐입니다.
오라클(, 우리에게는 알려지지 않음)이 상태 을 표시한다고 가정합니다. 각 양자 Gate(오라클 포함)의 동작을 단계별로 따라가며, 측정 시 어떤 상태 분포가 나타나는지 살펴봅니다. 맨 처음 상태는
Hadamard Gate의 정의를 사용하면:
이제 오라클이 목표 상태를 표시합니다:
이 상태에서 네 가지 가능한 결과 모두 동일한 측정 확률을 가집니다. 각각 의 가중치를 가지므로, 의 확률로 측정됩니다. 따라서 상태 이 "-" 위상으로 표시되었지만, 이것이 아직 해당 상태의 측정 확률 증가로 이어지지는 않습니다. 다음 Hadamard Gate 레이어를 적용합니다.
동류항을 합치면:
이제 이 을 제외한 모든 상태의 부호를 반전시킵니다:
마지막으로 마지막 Hadamard Gate 레이어를 적용합니다:
이 항들을 직접 결합해보면 결과가 실제로 다음과 같음을 확인할 수 있습니다:
즉, (잡음과 오류가 없는 경우) 을 측정할 확률은 100%이며, 다른 상태를 측정할 확률은 0입니다.
이 2-Qubit 예시는 특히 깔끔한 경우입니다. Grover 알고리즘이 항상 목표 상태를 100% 확률로 측정하는 결과를 내지는 않습니다. 알고리즘은 목표 상태를 측정할 확률을 증폭시키는 것이며, Grover 연산자를 두 번 이상 반복해야 할 수도 있습니다.
다음 섹션에서는 실제 IBM® 양자 컴퓨터를 사용하여 이 알고리즘을 실습해 봅니다.
기하학적 그림
위의 2-Qubit 예시는 소규모 경우에서 대수학이 어떻게 전개되는지 보여주었지만, Grover 알고리즘을 이해하는 훨씬 더 직관적인 방법이 있습니다. 바로 2차원 평면에서의 기하학적 반사 시퀀스로 이해하는 것입니다. 아래에서 이 그림을 설명합니다. 더 자세한 내용은 John Watrous의 강좌 양자 알고리즘의 기초에서도 확인할 수 있습니다.
평면 설정. 초기 중첩 상태 를 두 성분으로 분해할 수 있습니다. 우리가 찾고 있는 올바른 상태를 이라 부르고, 나머지 모든 상태를 뭉쳐서 이라 부릅니다. 정의에 따라 과 은 서로 직교하므로, 추상적인 2차원 공간에서 수직인 축으로 나타낼 수 있습니다. 은 이 두 성분의 선형 결합이므로, 축에 대해 작은 각도 를 이루며 위치합니다. 처음에는 상태의 아주 작은 부분만이 올바른 성분 에 있기 때문에, 에 가깝게 위치합니다.
반사. 필요한 핵심 수학적 사실은, 다음 형태의 연산자가
에 의해 정의된 축에 대해 임의의 상태를 반사한다는 것입니다. 그 이유를 보려면 두 가지 경우를 고려하세요. 방향의 상태는 변하지 않고, 에 수직인 상태는 부호가 반전됩니다. 다른 임의의 상태는 이 두 성분으로 분해되며, 연산자는 각각에 따라 작용합니다. 이것이 정확히 에 대한 반사입니다.
오라클 단계와 확산 단계 모두 이 기하학적 그림에서 반사로 표현될 수 있음이 밝혀졌습니다.
반사로서의 오라클. 오라클은 상태의 부호를 반전시키고 나머지는 그대로 둡니다. 이것은 축에 대한 반사와 같습니다.
반사로서의 확산. 확산 연산자도 반사임을 확인하는 것은 조금 더 까다롭습니다. 확산 연산자는
자체는 전체 영 상태에 대한 반사입니다. 이 아닌 모든 상태의 부호를 반전시키기 때문입니다. 이는 로 쓸 수 있습니다. 주변의 Hadamard 레이어는 효과적으로 기저 변환을 수행하여 반사 축을 변환합니다. 이 을 균일한 중첩 로 매핑함을 상기하세요. Hadamard는 자신의 역이므로 전체 식은
가 되어 에 대한 반사가 됩니다. 은 에 매우 가깝기 때문에(둘 다 에 거의 평행), 이 두 번째 반사는 상태를 시작점에서 각도만큼 보냅니다.
만큼의 회전. 이 두 반사의 합산 효과는 방향으로 만큼 회전하는 것입니다. Grover 연산자의 연속적인 각 반복은 상태를 씩 추가로 회전시킵니다.
최적 반복 횟수. 우리의 목표는 상태를 에 최대한 가깝게 회전시키는 것으로, 총 약 라디안(사분의 일 회전)만큼 회전해야 합니다. 각 반복이 를 기여하면, 최적 반복 횟수 는 다음을 만족합니다.
개의 상태 중 단일 해의 경우, 초기 각도는 (큰 에서)입니다. 대입하면,
바로 여기서 유명한 속도 향상이 나옵니다. 고전 탐색에서 필요한 번의 확인 대신 번의 반복만으로 목표에 도달할 수 있습니다.
더 일반적으로, 개의 전체 상태 중 개의 해 상태가 있는 경우, 최적 반복 횟수는
반복 횟수가 너무 많으면 을 지나쳐 목표 상태를 찾을 확률이 다시 감소하기 시작합니다. 올바른 반복 횟수를 찾는 것이 중요하지만, 노이즈가 있는 양자 하드웨어에서는 실험적으로 최적인 횟수가 이 이상적인 공식과 다를 수 있습니다.
Grover 알고리즘은 왜 유용한가요?
이 시점에서 이런 의문이 생길 수 있습니다. 우리는 목표 상태를 표시하는 오라클을 방금 구성했는데, 그것을 구성하려면 목표 상태를 알아야 했습니다. 그렇다면 실제로 무엇을 탐색하는 것일까요?
이것은 타당한 질문이며, 몇 가지 좋은 답변이 있습니다.
-
쿼리 모델은 이론적 도구입니다. 쿼리 계산 모델은 직접적으로 실용적이도록 설계된 것이 아닙니다. 그 목적은 문제를 오라클과 나머지 두 부분으로 분리하여 알고리즘 복잡도를 분석하는 깔끔한 방법을 제공하는 것입니다. 검증이 무료라면 탐색은 얼마나 어려운가요? 쿼리 수는 입력 크기에 따라 어떻게 확장되는가요? 실제 시스템이 정확히 이렇게 작동하지 않더라도 이것들은 유용한 질문입니다.
-
2인 활동으로도 생각할 수 있습니다. 한 사람은 목표 상태를 알고 오라클을 구성하며, 다른 사람은 내부를 들여다보지 않고 블랙박스로서 오라클을 사용하여 답을 찾습니다. 아래의 활동 2에서 파트너와 함께 정확히 이것을 수행하게 됩니다.
-
진폭 증폭은 광범위하게 유용한 서브루틴입니다. 이 첫 번째 데모가 순환적으로 보이더라도, 그 기저의 메커니즘인 *진폭 증폭(amplitude amplification)*은 양자 컴퓨팅에서 반복적으로 등장합니다. 우리가 여기서 실제로 구축하는 것은 더 복잡한 많은 양자 알고리즘에서 서브루틴으로 등장하는 도구에 대한 직관입니다.
-
답을 알지 못하고도 오라클을 구성할 수 있는 문제들이 있습니다. 핵심 통찰은 해를 찾기는 매우 어렵지만 주어진 해가 올바른지 확인하기는 매우 쉬운 문제 클래스 전체가 존재한다는 것입니다. 인수분해가 하나의 예입니다. 두 개의 큰 소수의 곱이 주어졌을 때 그 소수들이 무엇인지 결정하기는 극도로 어렵지만, 일단 소수들을 알면 곱해서 쉽게 검증할 수 있습니다. (인수분해에는 Grover 알고리즘보다 더 나은 알고리즘이 있습니다. Shor 알고리즘을 참조하세요. 하지만 이 특성을 가진 문제가 이것뿐인 것은 아닙니다.) 스도쿠, 제약 충족, 심지어 고전 게임 지뢰찾기도 모두 풀기는 어렵지만 확인하기는 쉬운 문제입니다.
이것이 왜 관련이 있을까요? 해가 만족해야 하는 모든 조건과 요구 사항을 알 수 있으며, 그 요구 사항을 오라클로 기능하는 양자 회로로 인코딩할 수 있다는 것을 의미합니다. 해 자체를 알지 못해도 가능합니다. Grover 알고리즘이 그것을 찾아줄 것입니다.
이러한 아이디어를 염두에 두고 몇 가지 예제를 살펴보겠습니다. 먼저 알고리즘의 논리를 따라갈 수 있도록 해 상태가 명확히 지정된 예제부터 시작합니다. 그런 다음 2인 활동으로 넘어가고, 마지막으로 답에 대한 지식이 아닌 문제 제약 조건에서 오라클을 구성하는 예제로 넘어갑니다.
일반 임포트 및 접근 방식
먼저 필요한 패키지를 임포트합니다.
# Built-in modules
import math
# Imports from Qiskit
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister
from qiskit.circuit.library import grover_operator, MCMTGate, ZGate
from qiskit.visualization import plot_distribution
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
이 튜토리얼을 비롯한 다양한 튜토리얼에서는 "Qiskit 패턴"이라고 알려진 양자 컴퓨팅 프레임워크를 사용합니다. 이 프레임워크는 워크플로를 다음 단계로 구분합니다.
- 1단계: 고전적 입력을 양자 문제로 매핑
- 2단계: 양자 실행을 위한 문제 최적화
- 3단계: Qiskit Runtime Primitive를 사용하여 실행
- 4단계: 후처리 및 고전적 분석
일반적으로 이 단계들을 따르되, 항상 명시적으로 레이블을 붙이지는 않을 수 있습니다.
활동 1: 단일 목표 상태 찾기
Step 1: Map classical inputs to a quantum problem
솔루션 상태에는 전체 위상(-1)을 적용하고 비솔루션 상태에는 영향을 주지 않는 위상 질의 Gate가 필요합니다. 다시 말해, Grover's algorithm에는 하나 이상의 표시된 계산 기저 상태를 지정하는 오라클이 필요하며, 여기서 "표시됨"은 위상이 -1인 상태를 의미합니다. 이는 제어-Z Gate 또는 Qubit에 대한 다중 제어 일반화를 사용하여 구현합니다. 동작 방식을 이해하기 위해 비트 문자열 {110}의 구체적인 예를 살펴봅시다. 상태에 작용하여 일 때 위상을 적용하는 Circuit을 원합니다(이진 문자열의 순서가 반전된 것은 Qiskit 표기법 때문으로, 최하위 (주로 0번) Qubit이 오른쪽에 위치합니다).
따라서 다음을 수행하는 Circuit 가 필요합니다.
다중 제어 다중 타겟 Gate(MCMTGate)를 사용하면 모든 Qubit에 의해 제어되는 Z Gate를 적용할 수 있습니다(모든 Qubit이 상태일 때 위상을 반전). 물론 원하는 상태의 일부 Qubit은 일 수 있습니다. 따라서 그러한 Qubit에는 먼저 X Gate를 적용하고, 다중 제어 Z Gate를 수행한 후, 다시 X Gate를 적용하여 변경을 되돌려야 합니다. MCMTGate는 다음과 같은 형태입니다.
mcmt_ex = QuantumCircuit(3)
mcmt_ex.compose(MCMTGate(ZGate(), 3 - 1, 1), inplace=True)
mcmt_ex.draw(output="mpl", style="iqp")

제어 과정에 많은 Qubit이 참여할 수 있지만(여기서는 세 개), 어떤 단일 Qubit도 타겟으로 지정되지 않습니다. 전체 상태가 전반적인 "-" 부호(위상 반전)를 얻기 때문에, 이 Gate는 모든 Qubit에 동등하게 영향을 미칩니다. 이는 단일 제어 Qubit과 단일 타겟 Qubit을 갖는 CX Gate와 같은 다른 다중 qubit Gate와는 다릅니다.
아래 코드에서는 앞서 설명한 동작을 수행하는 위상 질의 Gate(또는 오라클)를 정의합니다. 이 오라클은 비트 문자열 표현을 통해 정의된 하나 이상의 입력 기저 상태를 표시합니다. MCMT Gate는 다중 제어 Z-Gate를 구현하는 데 사용됩니다.
def grover_oracle(marked_states):
"""Build a Grover oracle for multiple marked states
Here we assume all input marked states have the same number of bits
Parameters:
marked_states (str or list): Marked states of oracle
Returns:
QuantumCircuit: Quantum circuit representing Grover oracle
"""
if not isinstance(marked_states, list):
marked_states = [marked_states]
# Compute the number of qubits in circuit
num_qubits = len(marked_states[0])
qc = QuantumCircuit(num_qubits)
# Mark each target state in the input list
for target in marked_states:
# Flip target bitstring to match Qiskit bit-ordering
rev_target = target[::-1]
# Find the indices of all the '0' elements in bitstring
zero_inds = [
ind for ind in range(num_qubits) if rev_target.startswith("0", ind)
]
# Add a multi-controlled Z-gate with pre- and post-applied X-gates (open-controls)
# where the target bitstring has a '0' entry
qc.x(zero_inds)
qc.compose(MCMTGate(ZGate(), num_qubits - 1, 1), inplace=True)
qc.x(zero_inds)
return qc
이제 특정 "표시된" 상태를 목표로 선택하고 방금 정의한 함수를 적용합니다. 어떤 종류의 Circuit이 생성되었는지 확인해 봅시다.
marked_states = ["1110"]
oracle = grover_oracle(marked_states)
oracle.draw(output="mpl", style="iqp")

Qubit 13이 상태이고 qubit 0이 처음에 상태라면, 첫 번째 X Gate가 qubit 0을 로 반전시켜 모든 Qubit이 상태가 됩니다. 이 경우 MCMT Gate가 원하는 대로 전반적인 부호 변경 또는 위상 반전을 적용합니다. 그 외의 경우에는 qubit 13이 상태이거나 qubit 0이 으로 반전되어 위상 반전이 적용되지 않습니다. 이 Circuit이 실제로 원하는 상태 , 즉 비트 문자열 {1110}을 표시함을 확인할 수 있습니다.
완전한 Grover 연산자는 위상 질의 Gate(오라클), Hadamard 레이어, 연산자로 구성됩니다. 위에서 정의한 오라클로부터 내장 grover_operator를 사용하여 이를 구성할 수 있습니다.
grover_op = grover_operator(oracle)
grover_op.decompose(reps=0).draw(output="mpl", style="iqp")
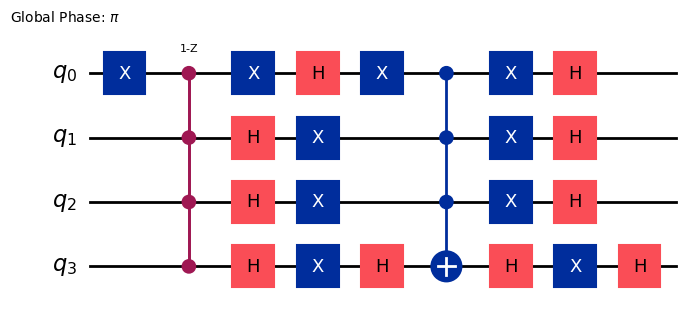
위의 기하학적 그림에서 논의한 바와 같이, Grover 연산자를 여러 번 적용해야 할 수 있습니다. 노이즈가 없는 경우에 목표 상태의 진폭을 최대화하는 최적 반복 횟수 는
여기서 은 해 상태의 수이고 은 전체 상태의 수입니다. 현대의 노이즈가 있는 양자 컴퓨터에서는 실험적으로 최적인 반복 횟수가 다를 수 있지만 — 여기서는 을 사용하여 이 이론적 최적값을 계산하고 적용합니다.
optimal_num_iterations = math.floor(
math.pi / (4 * math.asin(math.sqrt(len(marked_states) / 2**grover_op.num_qubits)))
)
print(optimal_num_iterations)
3
이제 모든 가능한 상태의 중첩을 생성하는 초기 Hadamard Gate를 포함하고, 최적 횟수만큼 Grover 연산자를 적용하는 Circuit을 구성해 보겠습니다.
qc = QuantumCircuit(grover_op.num_qubits)
# Create even superposition of all basis states
qc.h(range(grover_op.num_qubits))
# Apply Grover operator the optimal number of times
qc.compose(grover_op.power(optimal_num_iterations), inplace=True)
# Measure all qubits
qc.measure_all()
qc.draw(output="mpl", style="iqp")
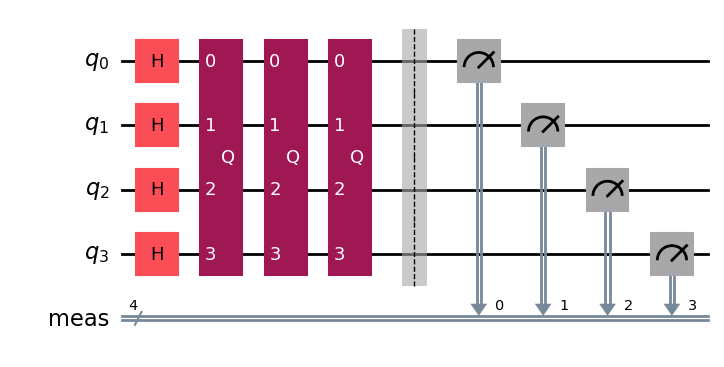
Grover Circuit이 완성되었습니다!
Step 2: Optimize problem for quantum hardware execution
추상적인 양자 Circuit을 정의했지만, 실제로 사용할 양자 컴퓨터에 기본으로 탑재된 Gate로 재작성해야 합니다. 또한 양자 컴퓨터에서 어떤 Qubit을 사용할지 지정해야 합니다. 이러한 이유 등으로 Circuit을 트랜스파일해야 합니다. 먼저 사용할 양자 컴퓨터를 지정합니다.
아래에는 최초 사용 시 자격 증명을 저장하는 코드가 있습니다. 자격 증명을 환경에 저장한 후에는 노트북에서 해당 정보를 삭제하여, 노트북을 공유할 때 자격 증명이 실수로 노출되지 않도록 하세요. 자세한 안내는 IBM Cloud 계정 설정 및 신뢰할 수 없는 환경에서 서비스 초기화를 참고하세요.
# To run on hardware, select the backend with the fewest number of jobs in the queue
from qiskit_ibm_runtime import QiskitRuntimeService
# Syntax for first saving your token. Delete these lines after saving your credentials.
# QiskitRuntimeService.save_account(channel='ibm_quantum_platform',
# instance = '<YOUR_IBM_INSTANCE_CRN>', token='<YOUR_API_KEY>', overwrite=True, set_as_default=True)
# service = QiskitRuntimeService(channel='ibm_quantum_platform')
# Load saved credentials
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
backend.name
qiskit_runtime_service._resolve_cloud_instances:WARNING:2025-08-08 14:14:19,931: Default instance not set. Searching all available instances.
'ibm_brisbane'
이제 사전 설정된 패스 매니저를 사용하여 선택한 Backend에 맞게 양자 Circuit을 최적화합니다.
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
circuit_isa = pm.run(qc)
# The transpiled circuit will be very large. Only draw it if you are really curious.
# circuit_isa.draw(output="mpl", idle_wires=False, style="iqp")
이 시점에서 트랜스파일된 양자 Circuit의 깊이가 상당하다는 점을 짚어 둘 필요가 있습니다.
print("The total depth is ", circuit_isa.depth())
print(
"The depth of two-qubit gates is ",
circuit_isa.depth(lambda instruction: instruction.operation.num_qubits == 2),
)
The total depth is 439
The depth of two-qubit gates is 113
이 간단한 경우에도 실제로 꽤 큰 수입니다. 모든 양자 Gate(특히 2-Qubit Gate)는 오류와 노이즈의 영향을 받기 때문에, 100개 이상의 2-Qubit Gate로 이루어진 시퀀스는 qubit 성능이 매우 뛰어나지 않는 한 노이즈만 남게 됩니다. 실제로 어떻게 동작하는지 살펴봅시다.
Step 3: Qiskit 프리미티브를 사용하여 실행
많은 측정을 수행하고 가장 가능성이 높은 상태를 확인하려 합니다. 이러한 진폭 증폭은 Sampler Qiskit Runtime Primitive로 실행하기에 적합한 샘플링 문제입니다.
Qiskit Runtime SamplerV2의 run() 메서드는 PUB(Primitive Unified Block)의 이터러블을 인수로 받습니다. Sampler의 경우 각 PUB는 (circuit, parameter_values) 형식의 이터러블입니다. 하지만 최소한으로는 양자 Circuit의 목록만 있으면 됩니다.
# To run on a real quantum computer (this was tested on a Heron r2 processor and
# used 4 sec. of QPU time)
from qiskit_ibm_runtime import SamplerV2 as Sampler
sampler = Sampler(mode=backend)
sampler.options.default_shots = 10_000
result = sampler.run([circuit_isa]).result()
dist = result[0].data.meas.get_counts()
이 경험을 최대한 활용하려면 IBM Quantum에서 제공하는 실제 양자 컴퓨터에서 실험을 실행하는 것을 강력히 권장합니다. 하지만 QPU 시간을 모두 소진한 경우, 아래 줄의 주석을 해제하여 시뮬레이터로 이 활동을 완료할 수 있습니다.
# To run on local simulator:
# from qiskit.primitives import StatevectorSampler as Sampler
# sampler = Sampler()
# result = sampler.run([qc]).result()
# dist = result[0].data.meas.get_counts()
Step 4: 후처리 및 원하는 고전적 형식으로 결과 반환하기
이제 샘플링 결과를 히스토그램으로 표시할 수 있습니다.
plot_distribution(dist)
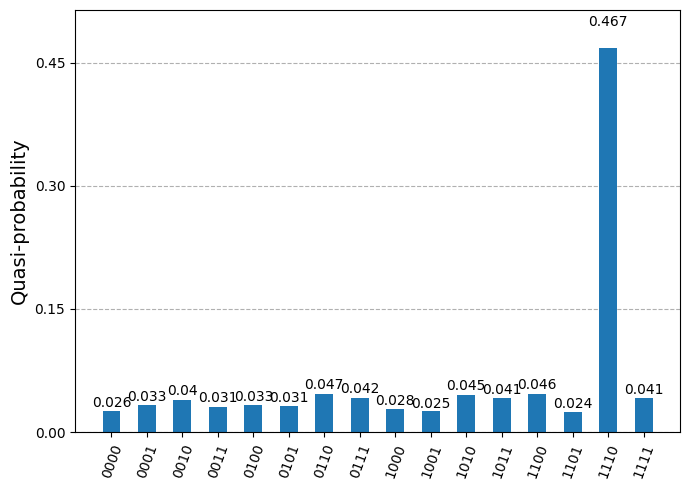
Grover's algorithm이 다른 옵션보다 월등히 높은 확률로, 적어도 한 자릿수 이상 높은 확률로 원하는 상태를 반환했음을 확인할 수 있습니다. 다음 활동에서는 알고리즘을 쿼리 알고리즘의 2인 워크플로에 더 부합하는 방식으로 사용합니다.
이해도 확인
아래 질문을 읽고 답을 생각해 본 후, 삼각형을 클릭하여 해답을 확인하세요.
방금 개의 가능한 상태 중에서 단일 솔루션을 검색했습니다. Grover 연산자의 최적 반복 횟수를 으로 결정했습니다. (a) 여러 솔루션 중 하나를 검색하거나, (b) 더 많은 가능한 상태 공간에서 단일 솔루션을 검색한다면, 이 최적 횟수는 증가했을까요, 감소했을까요?
정답:
솔루션의 수가 전체 솔루션 공간에 비해 작다면, 사인 함수를 작은 각도에서 전개하여 다음을 사용할 수 있음을 상기하세요.
(a) 위 식에서 솔루션 상태의 수가 증가하면 반복 횟수는 감소합니다. 비율이 여전히 작다면, 가 어떻게 감소하는지 다음과 같이 설명할 수 있습니다: .
(b) 가능한 솔루션의 공간()이 커질수록 필요한 반복 횟수는 증가하지만, 처럼만 증가합니다.
목표 비트 문자열의 크기를 임의로 늘려도 목표 상태의 확률 진폭이 다른 상태보다 적어도 한 자릿수 이상 높다고 가정해 봅시다. 이것이 Grover's algorithm을 사용하여 목표 상태를 신뢰할 수 있게 찾을 수 있다는 의미일까요?
정답:
아닙니다. 20개의 Qubit으로 첫 번째 활동을 반복하고 num_shots = 10,000번 양자 Circuit을 실행한다고 가정합시다. 균일한 확률 분포라면 모든 상태가 의 확률로 측정될 것입니다. 목표 상태의 측정 확률이 비솔루션의 10배이고(각 비솔루션의 확률이 그에 따라 약간 감소하면), 목표 상태가 단 한 번이라도 측정될 확률은 약 10%밖에 되지 않습니다. 목표 상태가 여러 번 측정될 가능성은 매우 낮아, 무작위로 얻은 수많은 비솔루션 상태와 구별하기 어렵게 됩니다. 다행히도 오류 억제 및 완화를 사용하면 더 높은 신뢰도의 결과를 얻을 수 있습니다.
활동 2: 정확한 쿼리 알고리즘 워크플로
이 활동은 첫 번째 활동과 동일하게 시작하되, 이번에는 다른 Qiskit 동료와 짝을 이루게 됩니다. 여러분은 비밀 비트 문자열을 선택하고, 파트너는 (일반적으로) 다른 비트 문자열을 선택합니다. 각자 오라클로 작동하는 양자 Circuit을 생성하고 서로 교환합니다. 그런 다음 그 오라클로 Grover's algorithm을 사용하여 파트너의 비밀 비트 문자열을 알아냅니다.
Step 1: 고전적 입력을 양자 문제로 변환하기
위에서 정의한 grover_oracle 함수를 사용하여 하나 이상의 표시 상태(marked state)에 대한 오라클 회로를 구성합니다. 파트너에게 표시한 상태의 수를 알려주어야 합니다. 그래야 파트너가 Grover 연산자를 최적 횟수만큼 적용할 수 있습니다. 비트스트링을 너무 길게 만들지 마세요. 3~5비트 정도면 큰 어려움 없이 동작합니다. 비트스트링이 길어지면 깊이가 깊은 회로가 생성되어 오류 완화(error mitigation)와 같은 고급 기법이 필요합니다.
# Modify the marked states to mark those you wish to target.
marked_states = ["1000"]
oracle = grover_oracle(marked_states)
이제 목표 상태의 위상(phase)을 반전시키는 양자 회로가 만들어졌습니다. 아래 구문을 사용하여 이 회로를 my_circuit.qpy로 저장할 수 있습니다.
from qiskit import qpy
# Save to a QPY file at a location where you can easily find it.
# You might want to specify a global address.
with open("C:\\Users\\...put your own address here...\\my_circuit.qpy", "wb") as f:
qpy.dump(oracle, f)
이 파일을 파트너에게 전송합니다(이메일, 메시징 서비스, 공유 저장소 등 원하는 방법을 사용하세요). 파트너도 자신의 회로를 전송해 달라고 요청하세요. 파일을 쉽게 찾을 수 있는 위치에 저장해 두세요. 파트너의 회로를 받은 후 시각화해 볼 수도 있지만, 이는 쿼리 모델을 깨뜨립니다. 즉, 우리는 오라클을 검사하여 대상 상태를 파악하는 것이 아니라, 오라클을 쿼리(사용)하는 상황을 모델링하고 있습니다.
from qiskit import qpy
# Load the circuit from your partner's qpy file from the folder where you saved it.
with open("C:\\Users\\...file location here...\\my_circuit.qpy", "rb") as f:
circuits = qpy.load(f)
# qpy.load always returns a list of circuits
oracle_partner = circuits[0]
# You could visualize the circuit, but this would break the model of a query algorithm.
# oracle_partner.draw("mpl")
파트너에게 인코딩한 목표 상태의 수를 물어보고 아래에 입력합니다.
# Update according to your partner's number of target states.
num_marked_states = 1
이 값은 다음 식에서 최적 Grover 반복 횟수를 결정하는 데 사용됩니다.
grover_op = grover_operator(oracle_partner)
optimal_num_iterations = math.floor(
math.pi / (4 * math.asin(math.sqrt(num_marked_states / 2**grover_op.num_qubits)))
)
qc = QuantumCircuit(grover_op.num_qubits)
qc.h(range(grover_op.num_qubits))
qc.compose(grover_op.power(optimal_num_iterations), inplace=True)
qc.measure_all()
Step 2: 양자 하드웨어 실행을 위한 문제 최적화
이 단계는 이전과 동일하게 진행됩니다.
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
backend.name
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
circuit_partner_isa = pm.run(qc)
Step 3: Qiskit 프리미티브를 사용하여 실행하기
이 과정도 첫 번째 활동과 동일합니다.
# To run on a real quantum computer (this was tested on a Heron r2 processor and used
# 4 seconds of QPU time)
from qiskit_ibm_runtime import SamplerV2 as Sampler
sampler = Sampler(mode=backend)
sampler.options.default_shots = 10_000
result = sampler.run([circuit_partner_isa]).result()
dist = result[0].data.meas.get_counts()
Step 4: 후처리 및 원하는 고전적 형식으로 결과 반환하기
이제 샘플링 결과의 히스토그램을 표시합니다. 하나 이상의 상태가 다른 상태보다 측정 확률이 훨씬 높게 나타나야 합니다. 이 결과를 파트너에게 알리고 목표 상태를 올바르게 찾았는지 확인합니다. 기본적으로 표시되는 히스토그램은 첫 번째 활동에서 사용한 회로의 결과입니다. 파트너의 회로에서는 다른 결과가 나와야 합니다.
plot_distribution(dist)
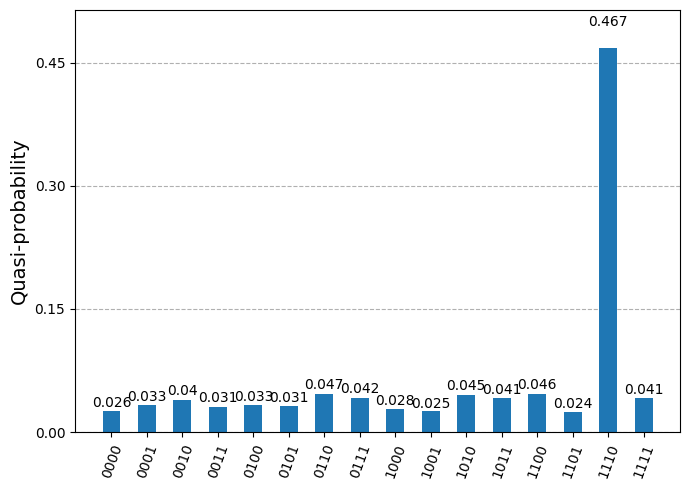
이해도 확인
아래 질문이나 지시 사항을 읽고, 답을 생각해 보거나 파트너와 함께 과정을 이야기해 보세요. 삼각형을 클릭하면 힌트나 제안을 확인할 수 있습니다.
파트너의 목표 상태를 올바르게 찾았을 것입니다. 그렇지 않다면 파트너와 함께 무엇이 잘못되었는지 확인해 보세요. 몇 가지 아이디어를 보려면 아래를 클릭하세요.
힌트:
- 파트너의 회로를 시각화/그려보고 올바르게 불러왔는지 확인하세요.
- 사용된 회로를 비교하고 예상 결과와 실제 결과를 비교해 보세요.
- 비트스트링이 너무 길지 않은지, Grover 반복 횟수가 지나치게 많지 않은지 회로 깊이를 확인하세요.
아직 하지 않았다면 파트너가 보낸 오라클 회로를 그려보세요. 각 Gate의 효과를 설명하고 목표 상태가 무엇인지 논리적으로 설명해 볼 수 있는지 확인해 보세요. 표시 상태가 하나인 경우가 여러 개인 경우보다 훨씬 쉬울 것입니다.
힌트:
- 오라클의 역할은 목표 상태의 부호를 반전시키는 것임을 떠올리세요.
- MCMTGate는 제어에 관여하는 모든 Qubit이 상태일 때만 부호를 반전시킨다는 점을 기억하세요.
- 목표 상태에서 특정 Qubit이 이미 이라면 해당 Qubit에 아무것도 할 필요가 없습니다. 목표 상태에서 특정 Qubit이 이고 MCMTGate가 부호를 반전시키도록 하려면, 오라클에서 해당 Qubit에
XGate를 적용한 뒤 MCMTGate 이후XGate를 다시 적용하여 되돌려야 합니다.
Grover 연산자의 반복 횟수를 하나 줄여서 실험을 반복해 보세요. 여전히 정확한 답을 얻을 수 있나요? 그 이유는 무엇인가요?
안내:
아마 정확한 답을 얻을 수 있을 것입니다. 단, 인코딩된 해의 수에 따라 달라질 수 있습니다. 이는 미묘한 점을 드러냅니다. "최적" Grover 반복 횟수는 표시 상태를 측정할 확률을 최대로 만드는 횟수입니다. 하지만 그보다 적은 반복 횟수로도 표시 상태가 다른 상태보다 훨씬 높은 확률을 가질 수 있습니다. 따라서 최적 횟수보다 적게 반복해도 충분할 수 있습니다. 이렇게 하면 회로 깊이가 줄어들어 오류율도 낮아집니다.
여기서 식별된 "최적 횟수"보다 Grover 반복 횟수를 줄이고 싶은 이유는 무엇일까요?
답변:
"최적" Grover 반복 횟수는 노이즈가 없는 환경에서 표시 상태를 측정할 확률을 최대로 만드는 횟수입니다. 하지만 그보다 적은 반복 횟수로도 표시 상태가 다른 상태보다 훨씬 높은 확률을 가질 수 있습니다. 따라서 최적 횟수보다 적게 반복해도 충분할 수 있습니다. 이렇게 하면 회로 깊이가 줄어들어 오류율도 낮아집니다.
Activity 3: Grover 알고리즘으로 지뢰찾기 격자 풀기
이전 섹션에서 우리는 Grover 알고리즘이 답에 대한 지식이 아닌 문제의 제약 조건에서 오라클을 구성할 수 있을 때 진정으로 유용해진다고 언급했습니다. 지뢰찾기는 완벽한 예입니다. 번호가 매겨진 셀들은 인접한 지뢰가 몇 개인지 알려주고, 그 제약 조건들이 지뢰의 위치를 완전히 결정하지만 — 구성을 찾으려면 탐색이 필요합니다.
지뢰찾기는 NP-완전임이 증명되었습니다. 풀기는 어렵지만 확인하기는 쉽습니다. 따라서 Grover 알고리즘의 자연스러운 후보입니다. 물론 현재 노이즈가 있는 양자 컴퓨터에서 전체 99 격자를 풀 수는 없습니다. Circuit이 너무 깊을 것입니다. 대신, 미래의 오류 허용(fault-tolerant) 기계에서 더 큰 보드에 접근하는 방식을 장난감 데모로 보여주기 위해 작은 격자를 사용할 것입니다.
몇 가지 중요한 주의 사항이 있습니다. Grover 알고리즘은 비구조적 고전 탐색에 대해서만 이차적 속도 향상을 제공합니다. 지뢰찾기는 영리한 고전 알고리즘이 활용할 수 있는 구조를 거의 확실히 갖고 있습니다. 그리고 지수적으로 성장하는 탐색 공간에서는, 향상도 한계가 있습니다. 하지만 그런 우려는 제쳐두고, 이 장난감 문제를 사용하여 문제 제약 조건이 양자 오라클에 어떻게 인코딩되는지 설명하겠습니다.
격자
다음은 우리의 작은 지뢰찾기 격자입니다:

각 빈 셀은 지뢰가 있는지 여부를 나타내는 이진 변수로 표현할 수 있습니다. 이를 , , 로 표시하며, 은 해당 셀에 지뢰가 있음을, 은 없음을 의미합니다:

우리는 이것을 약 반 초 안에 머릿속으로 풀 수 있지만, 훨씬 더 어려운 보드를 양자 컴퓨터로 어떻게 접근할 수 있는지 설명하기 위해 이 장난감 문제를 사용합니다.
제약 조건 인코딩
각 번호가 매겨진 셀은 인접한 빈 셀에 조건을 부여합니다. 이 조건들을 양자 회로에 인코딩할 수 있는 불리언 식으로 표현해야 합니다.
과 에 인접한 "1" 셀은 그 중 정확히 하나가 지뢰를 포함한다고 말합니다. 이것은 정확히 배타적 OR(XOR) 연산 이며, 입력 중 정확히 하나가 참일 때 참을 반환합니다:
마찬가지로, 다른 "1" 셀(과 에 인접)은 다음을 줍니다:
"2" 셀은 세 개의 빈 셀 중 두 개가 지뢰를 포함해야 한다고 말합니다. XOR은 홀짝성 연산이므로, 는 변수 중 홀수 개가 참일 때 참을 반환합니다. 짝수 개(구체적으로 두 개)가 참이기를 원하므로, 로 부정합니다:
이 식 자체만으로는 상태의 Qubit이 0개 또는 2개일 때 만족됩니다. 홀짝성에 관한 진술이기 때문입니다. 하지만 각각 최소 하나의 지뢰를 요구하는 다른 두 절과 결합하면, 유일하게 만족하는 할당은 정확히 지뢰 두 개입니다.
세 조건 모두 동시에 만족되어야 하므로, AND 기호 로 연결합니다:
Step 1: Map classical inputs to a quantum problem
이제 이 불리언 식을 오라클로 기능하는 양자 회로에 인코딩해야 합니다. XOR의 양자 버전은 CX(CNOT) Gate로 구현할 수 있습니다. 데이터 Qubit에서 작업 공간(보조) Qubit으로 두 개의 CX Gate를 적용하면 효과적으로 XOR을 계산하고 결과를 보조 Qubit에 저장합니다.
각 절에 하나씩 세 개의 작업 공간 Qubit을 도입합니다. 각 불리언 식의 결과를 해당 작업 공간 Qubit에 저장한 다음, 다중 제어 Z Gate를 사용하여 세 개의 작업 공간 Qubit이 모두 인(즉 모든 절이 동시에 만족되는) 3-Qubit 상태의 위상을 반전시킵니다.
아래 첫 번째 코드 셀에서, 오라클의 "계산" 반쪽을 구성합니다. 각 절을 평가하고 결과를 작업 공간 Qubit에 쓰는 부분입니다.
x = QuantumRegister(3, "x")
a = QuantumRegister(3, "a")
qc = QuantumCircuit(x, a)
# Clause 1: x0 XOR x1 -> stored in a[0]
qc.cx(x[0], a[0])
qc.cx(x[1], a[0])
# Clause 2: x1 XOR x2 -> stored in a[1]
qc.cx(x[1], a[1])
qc.cx(x[2], a[1])
# Clause 3: NOT(x0 XOR x1 XOR x2) -> stored in a[2]
qc.cx(x[0], a[2])
qc.cx(x[1], a[2])
qc.cx(x[2], a[2])
qc.x(a[2]) # The NOT
qc.draw("mpl", style="iqp")
이 시점에서, 각 절의 결과가 해당 작업 공간 Qubit에 저장됩니다. 이제 세 개의 작업 공간 Qubit을 모두 로 만드는 3-Qubit 데이터 상태가 마이너스 부호를 받아야 합니다. 이것을 다중 제어 Z Gate(타겟에서 Hadamard Gate가 앞뒤로 감싼 MCX Gate로 구현)로 수행합니다.
위상 반전을 적용한 후, **언컴퓨트(uncompute)**해야 합니다. 즉, 모든 절 평가 단계를 역순으로 되돌려 작업 공간 Qubit을 으로 재설정해야 합니다. 이것은 Grover 연산자의 후속 반복을 위해 작업 공간 Qubit이 깨끗해야 하기 때문에 필수적입니다.
# Multi-controlled Z: flip phase if all workspace qubits are |1>
qc.h(a[2])
qc.mcx([a[0], a[1]], a[2])
qc.h(a[2])
# Uncompute clause 3: NOT(x0 XOR x1 XOR x2)
qc.x(a[2])
qc.cx(x[2], a[2])
qc.cx(x[1], a[2])
qc.cx(x[0], a[2])
# Uncompute clause 2: x1 XOR x2
qc.cx(x[2], a[1])
qc.cx(x[1], a[1])
# Uncompute clause 1: x0 XOR x1
qc.cx(x[1], a[0])
qc.cx(x[0], a[0])
qc.draw("mpl", style="iqp")
이 Circuit이 우리의 오라클입니다. 세 가지 지뢰찾기 제약 조건을 모두 만족하는 데이터 qubit 상태의 위상을 반전시키고, 작업 공간 Qubit을 으로 되돌립니다.
이제 이 오라클에서 완전한 Grover 연산자를 구성합니다. reflection_qubits 인수에 주목하세요. 작업 공간 Qubit은 탐색 공간의 일부가 아니기 때문에, 데이터 qubit x만 전달합니다. 오라클이 적용되면 그 역할은 끝납니다.
grover_op = grover_operator(qc, reflection_qubits=x)
grover_op.decompose(reps=0).draw(output="mpl", style="iqp")
3개의 데이터 Qubit과 1개의 해 상태로, Grover 반복의 최적 횟수는 이므로, 두 번의 반복을 사용합니다. 데이터 Qubit에 Hadamard Gate를 적용하여 초기 중첩을 생성하고, Grover 연산자를 두 번 합성하고, 데이터 Qubit만 측정합니다.
x = QuantumRegister(3, "x")
a = QuantumRegister(4, "a")
meas = ClassicalRegister(3, "meas")
qc = QuantumCircuit(x, a, meas)
# Create superposition over the data qubits only
qc.h(x)
# Apply 2 iterations of the Grover operator
qc.compose(grover_op.power(2), inplace=True)
# Measure only the data qubits
qc.measure(x, meas)
qc.decompose().draw(output="mpl", style="iqp")
Step 2: Optimize problem for quantum hardware execution
이전과 마찬가지로, 목표 Backend에 맞게 Circuit을 트랜스파일합니다.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend.name)
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
circuit_isa = pm.run(qc)
이제 트랜스파일된 Circuit의 깊이를 확인할 수 있습니다. 지뢰찾기 오라클은 작업 공간 Qubit과 여러 CX Gate를 사용하기 때문에, 트랜스파일된 Circuit은 이전 활동들보다 더 깊을 것입니다.
print("The total depth is ", circuit_isa.depth())
print(
"The depth of two-qubit gates is ",
circuit_isa.depth(lambda instruction: instruction.operation.num_qubits == 2),
)
Step 3: Qiskit 프리미티브를 사용하여 실행
# To run on a real quantum computer (this was tested on a Heron r2 processor and
# used 4 sec. of QPU time)
from qiskit_ibm_runtime import SamplerV2 as Sampler
sampler = Sampler(mode=backend)
sampler.options.default_shots = 10_000
result = sampler.run([circuit_isa]).result()
dist = result[0].data.meas.get_counts()
# To run on local simulator:
# from qiskit.primitives import StatevectorSampler as Sampler
# sampler = Sampler()
# result = sampler.run([qc]).result()
# dist = result[0].data.meas.get_counts()
Step 4: 후처리 및 원하는 고전적 형식으로 결과 반환하기
plot_distribution(dist)
101 상태가 다른 어느 상태보다 훨씬 높은 확률로 나타나야 하며, 이는 과 에 지뢰가 위치함을 나타냅니다. 우리는 양자 컴퓨터를 사용하여 작은 지뢰찾기 게임을 풀었습니다!
물론, 지뢰찾기에 대한 최선의 고전 알고리즘은 가능한 모든 지뢰 구성을 통한 무차별 탐색보다 더 낫습니다. 격자의 구조를 활용합니다. Grover 알고리즘은 최대한 모호하게 설계된 극도로 어려운 보드에서만 이점을 제공할 것이며, 그렇더라도 이차적 속도 향상은 지수적 성장을 무한정 따라잡을 수 없습니다. 하지만 진정한 핵심은 기법입니다. 문제 제약 조건을 양자 오라클에 인코딩하는 것은 제약 충족, 조합 최적화 및 다른 많은 영역으로 확장되는 강력한 패턴입니다.
문제 및 핵심 개념:
핵심 개념:
이 모듈에서는 Grover 알고리즘의 주요 특징을 학습했습니다.
- 고전 비구조적 탐색 알고리즘은 탐색 공간의 크기 에 선형으로 비례하는 쿼리 수가 필요한 반면, Grover 알고리즘은 에 비례하는 쿼리 수만으로 탐색이 가능합니다.
- Grover 알고리즘은 일련의 연산(흔히 "Grover 연산자"라 불림)을 번 반복하며, 는 목표 상태가 측정될 확률을 최적화하도록 선택됩니다.
- Grover 알고리즘은 번보다 적게 반복해도 목표 상태의 확률을 증폭시킬 수 있습니다.
- Grover 알고리즘은 쿼리 기반 계산 모델에 적합하며, 한 사람이 탐색을 제어하고 다른 사람이 오라클을 제어/구성하는 상황에서 가장 적합합니다. 또한 다른 양자 계산의 서브루틴으로도 유용하게 활용될 수 있습니다.
- 지뢰찾기 예시에서 보여주었듯이, 오라클은 해에 대한 지식이 아닌 문제 제약 조건으로부터 구성될 수 있습니다.
참/거짓 문제:
-
참/거짓: Grover 알고리즘은 비구조적 탐색에서 단일 표시 상태를 찾는 데 필요한 쿼리 수에 있어 고전 알고리즘 대비 지수적 향상을 제공한다.
-
참/거짓: Grover 알고리즘은 해 상태가 측정될 확률을 반복적으로 증가시키는 방식으로 동작한다.
-
참/거짓: Grover 연산자를 더 많이 반복할수록 해 상태가 측정될 확률이 높아진다.
객관식 문제:
- 다음 문장을 가장 잘 완성하는 선택지를 고르세요. 현대 양자 컴퓨터에서 Grover 알고리즘을 성공적으로 활용하기 위한 최선의 전략은 Grover 연산자를...
- a. 한 번만 반복한다.
- b. 해 상태의 확률 진폭을 최대화하기 위해 항상 번 반복한다.
- c. 최대 번 반복하되, 해 상태를 두드러지게 만들기에 더 적은 횟수로도 충분할 수 있다.
- d. 10번 이상 반복한다.
- 특정 상태에 위상 반전을 표시하는 오라클 역할을 하는 위상 쿼리 Circuit이 아래에 있습니다. 다음 중 이 Circuit에 의해 표시되는 상태는 무엇입니까?

- a.
- b.
- c.
- d.
- e.
- f.
- 128개의 후보 중에서 표시된 상태 3개를 탐색하려고 합니다. 표시된 상태들의 진폭을 최대화하기 위한 Grover 연산자의 최적 반복 횟수는 얼마입니까?
- a. 1
- b. 3
- c. 5
- d. 6
- e. 20
- f. 33
토론 문제:
-
Grover 탐색으로 공식화할 수 있는 다른 문제들은 어떤 것이 있을까요? 해를 찾기는 어렵지만 해를 검증하기는 쉬운 문제를 생각해 보세요.
-
현대 양자 컴퓨터에서 Grover 알고리즘을 확장하는 데 어떤 문제가 있을 수 있는지 떠올릴 수 있나요?