양자 크릴로프 대각화
이 크릴로프 양자 대각화(KQD) 강의에서는 다음 질문에 답합니다.
- 크릴로프 방법이란 무엇인가요?
- 크릴로프 방법은 왜 작동하며, 어떤 조건에서 유효한가요?
- 양자 컴퓨팅은 어떤 역할을 하나요?
계산의 양자적 부분은 주로 참고문헌 [1]의 연구를 기반으로 합니다.
아래 동영상은 고전 컴퓨팅에서의 크릴로프 방법을 개괄적으로 소개하고, 그 활용 이유를 설명하며 양자 컴퓨팅이 이 작업 흐름에서 어떤 역할을 할 수 있는지 설명합니다. 이후 본문에서는 더 자세한 내용을 다루고, 고전적 방법과 양자 컴퓨터를 이용한 크릴로프 방법을 각각 구현합니다.
1. 크릴로프 방법 소개
__크릴로프 부분공간 방법__은 __크릴로프 부분공간__을 기반으로 하는 여러 방법들을 통칭합니다. 이 모든 방법을 이 강의에서 완전히 다루기는 어렵지만, 참고문헌 [2-4]에서 충분한 배경 지식을 얻을 수 있습니다. 여기서는 크릴로프 부분공간이 무엇인지, 고유값 문제를 푸는 데 어떻게, 왜 유용한지, 그리고 양자 컴퓨터에서 어떻게 구현할 수 있는지에 집중합니다.
정의: 대칭 양반정치(positive semi-definite) 행렬 가 주어졌을 때, 차수 의 크릴로프 공간 은 기준 벡터 에 행렬 의 거듭제곱을 차례로 곱해 얻는 벡터들로 생성되는 공간입니다. 단, 이어야 합니다.
위의 벡터들이 크릴로프 부분공간을 생성하긴 하지만, 이 벡터들이 서로 직교할 것이라고 기대할 이유는 없습니다. 따라서 __그람-슈미트 직교화__와 유사한 반복적인 정규직교화 과정을 흔히 사용합니다. 이 맥락에서는 새로운 벡터를 생성할 때마다 기존의 모든 벡터와 직교하도록 만드는데, 이를 __아놀디 반복(Arnoldi iteration)__이라고 합니다. 초기 벡터 에서 시작하여 다음 벡터 을 생성한 뒤, 이 두 번째 벡터에서 위로의 정사영을 빼서 직교성을 확보합니다. 즉,
이때 임을 쉽게 확인할 수 있습니다.
다음 벡터도 같은 방식으로 이전 두 벡터 모두에 직교하도록 생성합니다.
이 과정을 개의 벡터 모두에 대해 반복하면 크릴로프 공간의 완전한 정규직교 기저를 얻을 수 있습니다. 직교화 과정은 이 되는 순간 영벡터를 산출한다는 점에 유의하세요. 개의 직교 벡터가 전체 공간을 이미 생성하기 때문입니다. 또한 어떤 벡터가 의 고유벡터인 경우에도 이후의 모든 벡터가 그 벡터의 스칼라 배가 되어 영벡터가 산출됩니다.
1.1 간단한 예제: 손으로 풀어보는 크릴로프
크릴로프 부분공간을 생성하는 과정을 아주 작은 행렬에 직접 적용해 보겠습니다. 관심 행렬 는 다음과 같습니다.
이 작은 예제에서는 손으로도 고유벡터와 고유값을 쉽게 구할 수 있습니다. 여기서는 수치 해법을 제시합니다.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
나중에 비교할 수 있도록 결과를 정리해 둡니다.
크릴로프 부분공간의 차원 을 늘려가면서 이 과정이 어떻게 작동하는지(또는 실패하는지) 살펴보겠습니다. 이를 위해 다음 과정을 적용합니다.
- 임의로 선택한 벡터 (이미 정규화되어 있다면 )로 시작하여 전체 벡터 공간의 부분공간을 생성합니다.
- 전체 행렬 를 그 부분공간에 투영하고, 투영된 행렬 의 고유값을 구합니다.
- 그람-슈미트 직교화와 유사한 과정을 이용해 추가 벡터를 생성하여(정규직교성 보장) 부분공간의 크기를 늘립니다.
- 를 더 큰 부분공간에 투영하고 결과 행렬 의 고유값을 구합니다.
- 고유값이 수렴할 때까지(또는 이 장난감 예제에서는 원래 행렬 의 전체 벡터 공간을 생성할 때까지) 반복합니다.
일반적인 크릴로프 방법 구현에서는 부분공간을 구성할 때마다 매번 투영 행렬의 고유값 문제를 풀 필요가 없습니다. 원하는 차원의 부분공간을 구성한 후, 그 부분공간에 행렬을 투영하고 투영된 행렬을 대각화하면 됩니다. 각 부분공간 차원마다 투영과 대각화를 수행하는 것은 수렴 여부를 확인하기 위한 목적으로만 사용됩니다.
차원 :
임의 벡터를 선택합니다.
정규화되어 있지 않다면 정규화합니다.
이제 이 벡터 하나로 이루어진 부분공간에 행렬 를 투영합니다.
이것이 벡터 하나 만으로 이루어진 크릴로프 부분공간에 행렬을 투영한 결과입니다. 이 행렬의 고유값은 자명하게 4입니다. 이를 고유값의 0차 추정값으로 생각할 수 있습니다. 좋은 추정값은 아니지만 올바른 크기의 차수를 가집니다.
차원 :
부분공간에서 다음 벡터를 생성합니다. 이전 벡터에 를 적용하면 됩니다.
직교성을 확보하기 위해 이 벡터에서 이전 벡터 위로의 정사영을 뺍니다.
정규화되어 있지 않다면 정규화합니다. 이 경우 이미 정규화되어 있으므로
이제 두 벡터로 이루어진 부분공간에 행렬 A를 투영합니다.
이 행렬의 고유값을 구하는 문제가 남아 있습니다. 그러나 이 행렬은 원래 행렬보다 조금 더 작습니다. 매우 큰 행렬을 다루는 문제에서는 이처럼 작은 부분공간으로 작업하는 것이 큰 이점이 될 수 있습니다.
이는 여전히 좋은 추정값이 아니지만, 0차 추정보다는 나아졌습니다. 과정을 명확히 하기 위해 한 번 더 반복하겠습니다. 그러나 다음 반복에서 3×3 행렬을 대각화하게 되어 시간이나 계산 비용 면에서 이득이 없다는 점은 이 방법의 본래 취지를 희석시킵니다.
차원 :
부분공간에서 다음 벡터를 생성합니다. 이전 벡터에 A를 적용하면 됩니다.
직교성을 확보하기 위해 이전 두 벡터 모두에 대한 정사영을 뺍니다.
정규화되어 있지 않다면 정규화합니다. 이 경우 이미 정규화되어 있으므로
이제 이 벡터들로 이루어진 부분공간에 행렬 를 투영합니다.
이제 고유값을 구합니다.
이 고유값들은 원래 행렬 의 고유값과 정확히 일치합니다. 크릴로프 부분공간을 원래 행렬 의 전체 벡터 공간에 걸쳐 확장했으므로 당연한 결과입니다.
이 예제에서는 크릴로프 방법이 직접 대각화보다 특별히 더 쉬워 보이지 않을 수 있습니다. 실제로 이후 절에서 살펴보겠지만, 크릴로프 방법은 특정 행렬 차원 이상에서만 유리합니다. 이 방법은 극도로 큰 행렬의 고유값/고유벡터 문제를 푸는 데 활용하기 위해 소개하는 것입니다.
이것이 "손으로 직접" 풀어 보이는 유일한 예제입니다. 아래 2절에서는 계산을 이용한 예제를 보여줍니다.
용어 정리
흔한 오해 중 하나는 주어진 문제에 크릴로프 부분공간이 단 하나만 존재한다고 생각하는 것입니다. 물론 행렬을 적용할 수 있는 초기 벡터가 다양하므로, 가능한 크릴로프 부분공간도 여러 가지입니다. 이 강의에서는 특정 예제에서 이미 정의된 특정 크릴로프 부분공간을 가리킬 때에만 "그 크릴로프 부분공간"이라고 하겠습니다. 일반적인 문제 풀이 접근 방식에서는 "어떤 크릴로프 부분공간"이라고 표현합니다.
마지막으로 한 가지 더 정리하자면, "크릴로프 공간"이라고 부르는 것도 맞습니다. "크릴로프 부분공간"이라는 표현을 많이 쓰는 이유는, 초기 공간에서 더 작은 부분공간으로 행렬을 투영하는 맥락에서 주로 사용되기 때문입니다. 그 맥락에 맞게 이 강의에서도 주로 부분공간이라고 부르겠습니다.
이해도 확인
아래 질문을 읽고 답을 생각해 본 뒤, 삼각형을 클릭하여 각 해답을 확인하세요.
크릴로프 부분공간의 차원 을 관심 행렬의 차원 보다 크게 확장하는 것이 (a) 유용하지 않은 이유, (b) 불가능한 이유를 설명하세요.
답:
(a) 벡터를 생성하면서 정규직교화를 수행하므로, 개의 벡터가 모이면 완전한 기저를 형성합니다. 이 기저의 선형 결합으로 공간 내의 모든 벡터를 표현할 수 있습니다. (b) 직교화 과정은 새 벡터에서 이전 모든 벡터 위로의 정사영을 빼는 작업입니다. 이전 벡터들이 이미 전체 벡터 공간을 생성하고 있다면, 전체 부분공간에 대한 정사영을 빼면 항상 영벡터가 남습니다.
한 동료 연구자가 작은 장난감 행렬에 크릴로프 방법을 적용하는 과정을 동료들에게 시연하려고 합니다. 이 연구자는 다음 행렬과 초기 벡터를 사용할 계획입니다.
와
이 선택에 문제가 있나요? 동료에게 어떤 조언을 해주겠습니까?
답:
동료가 실수로 고유벡터를 초기 벡터로 선택했습니다. 초기 벡터에 행렬을 적용하면 그 벡터의 스칼라 배만 반환되므로 차원이 증가하는 부분공간을 생성할 수 없습니다. 초기 벡터가 고유벡터가 아닌 다른 벡터를 선택하도록 조언하세요.
적절한 새 초기 벡터를 선택하여 아래 행렬에 크릴로프 방법을 적용하세요. 크릴로프 부분공간의 0차 및 1차에서 최솟값 고유값의 추정값을 적어 보세요.
답:
초기 벡터 선택에 따라 다양한 답이 가능합니다. 여기서는 다음을 선택합니다.
을 구하기 위해 에 를 한 번 적용한 뒤, 에 직교하도록 만듭니다.
0차에서 크릴로프 부분공간으로의 투영은
1차에서 이 크릴로프 부분공간으로의 투영은
손으로도 계산할 수 있지만, numpy를 사용하면 가장 간편합니다.
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
출력:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
최솟값 고유값 추정값은 -0.414입니다.
1.2 Krylov 방법의 유형
"Krylov 부분공간 방법"은 대형 선형 시스템 및 고유값 문제를 푸는 데 사용되는 여러 반복적 기법을 통칭합니다. 이 모든 방법의 공통점은 Krylov 부분공간으로부터 근사 해를 구성한다는 것입니다.
여기서 은 초기 추정값입니다(참고문헌 [5] 참조). 이 방법들은 수렴 속도, 메모리 사용량, 전체 계산 비용 등의 요소를 균형 있게 고려하면서 이 부분공간에서 최적의 근사값을 선택하는 방식에서 차이가 있습니다. 이 단원의 초점은 Krylov 부분공간 방법의 맥락에서 양자 컴퓨팅을 활용하는 것이며, 이러한 방법들에 대한 포괄적인 논의는 범위를 벗어납니다. 아래의 간략한 정의는 맥락 파악을 위한 것으로, 이 방법들을 더 깊이 탐구하기 위한 몇 가지 참고문헌을 포함합니다.
켤레 기울기(CG, conjugate gradient) 방법: 이 방법은 대칭 양정치 선형 시스템을 푸는 데 사용됩니다[6]. 각 반복 단계에서 오차의 -노름을 최소화하므로, 이산화된 타원형 편미분방정식(PDE)에서 비롯된 시스템에 특히 효과적입니다[7]. 다음 절에서는 이 접근 방식을 사용하여 Krylov 부분공간이 선형 시스템의 개선된 해를 탐색하기 위한 효과적인 부분공간인 이유를 설명합니다.
일반화 최소 잔차(GMRES, generalized minimal residual) 방법: 이 방법은 일반적인 비대칭 선형 시스템을 푸는 데 설계되었습니다. 각 반복 단계에서 Krylov 공간에 대한 잔차 노름을 최소화하므로 강건하지만, 대형 시스템에서는 메모리 사용량이 많을 수 있습니다[7].
최소 잔차(MINRES, minimal residual) 방법: 이 방법은 대칭 부정치 선형 시스템을 푸는 데 사용됩니다. GMRES와 유사하지만 행렬의 대칭성을 활용하여 계산 비용을 줄입니다[8].
주목할 만한 다른 접근 방식으로는 고유값 문제를 위한 Arnoldi 방법과 밀접하게 관련된 완전 직교화 방법(FOM, full orthogonalization method), 쌍켤레 기울기(BiCG, bi-conjugate gradient) 방법, 그리고 __유도 차원 축소(IDR, induced dimension reduction) 방법__이 있습니다.
1.3 Krylov 부분공간 방법이 효과적인 이유
여기서는 최급강하법(steepest descent)의 관점을 통해, Krylov 부분공간 방법이 고유벡터 근사값의 반복적 정제를 통해 행렬 고유값을 효율적으로 근사하는 방법임을 설명합니다. 기저 상태의 초기 추정값이 주어졌을 때, 가장 빠른 수렴을 이끌어내는 초기 추정값에 대한 연속적 보정의 공간이 바로 Krylov 부분공간임을 논증합니다. 단, 수렴 거동에 대한 엄밀한 증명은 다루지 않습니다.
관심 행렬 가 대칭 양정치라고 가정합니다. 이를 통해 위에서 언급한 CG 방법과의 관련성이 가장 잘 드러납니다. 여기서는 희소성에 대한 가정을 하지 않으며, 가 에르미트 행렬이어야 한다고 주장하는 것도 아닙니다(에르미트 행렬이어야 하는 것은 해밀토니안인 경우입니다).
일반적으로 다음 형태의 문제를 풀고자 합니다.
으로 볼 수도 있는데, 여기서 는 어떤 상수이며, 이는 고유값 문제에 해당합니다. 하지만 현재 문제 설정은 보다 일반적으로 유지합니다.
근사 해인 벡터 에서 시작합니다. 이 추정값 과 1.1절의 사이에 유사점이 있지만, 여기서는 이를 활용하지 않습니다. 추정값 에는 오차가 있으며, 이를 이라 합니다.
또한 잔차 를 다음과 같이 정의합니다.
여기서 대문자 은 잔차를 Krylov 부분공간의 차원 과 구별하기 위해 사용합니다.

이제 다음 형태의 보정 단계를 수행하고자 합니다.
이를 통해 근사값이 개선되기를 기대합니다. 여기서 은 아직 결정되지 않은 벡터입니다. 보정 후의 오차를 이라 하면,

행렬에 의해 변환될 때 오차가 어떻게 동작하는지에 관심이 있습니다. 따라서 오차의 -노름을 계산해 봅니다.
여기서 의 대칭성과 을 이용하였습니다. 는 에 무관한 상수입니다. 1.2절에서 언급했듯이, 오차의 -노름이 최소화할 수 있는 유일한 양은 아니지만 좋은 선택입니다. 보정 벡터 의 선택에 따라 이 값이 어떻게 달라지는지 살펴봅니다. 함수 를 다음과 같이 정의합니다.
는 보정값 의 함수로서 -노름으로 측정한 오차 입니다. 따라서 을 최소화하는 을 선택하고자 합니다. 이를 위해 의 기울기를 계산합니다. 의 대칭성을 이용하면
기울기는 최급상승 방향을 가리키므로, 그 반대 방향이 함수가 가장 빠르게 감소하는 방향, 즉 최급강하 방향입니다. 초기 추정값 에서 일 때, 따라서 함수 는 잔차 방향으로 가장 많이 감소합니다. 그러므로 초기 선택은 어떤 스칼라 에 대해 를 추가함으로써 가장 큰 이득을 얻을 수 있습니다.
다음 단계에서도 마찬가지로 벡터 을 선택하여 현재 근사값에 더합니다. 앞과 동일한 논리로 어떤 스칼라 에 대해 을 선택합니다. 이를 반복하면 번째 반복에서의 벡터는
즉, 개선된 추정값을 선택하는 공간을 , 등을 순서대로 추가하여 구성하게 됩니다. 번째 추정 벡터는 다음 공간에 속합니다.
이제 다음 관계식을 이용하면
다음이 성립함을 알 수 있습니다.
즉, 올바른 해 을 가장 효율적으로 근사하기 위해 구성하는 공간은 에 행렬 를 연속적으로 적용하여 구성되는 공간과 정확히 일치합니다. Krylov 부분공간은 바로 연속적인 최급강하 방향의 벡터들로 생성되는 공간입니다.
마지막으로, 이 접근 방식의 스케일링에 대한 수치적 주장은 하지 않았으며, 희소 행렬에 대한 비교 이점도 논의하지 않았음을 다시 한번 강조합니다. 이는 오직 Krylov 부분공간 방법의 사용을 동기화하고 직관적인 이해를 돕기 위한 것입니다. 이제 이 방법들의 수치적 거동을 탐구해 보겠습니다.
이해도 확인
아래 질문을 읽고 답을 생각한 후, 삼각형을 클릭하여 정답을 확인하세요.
위의 과정에서 오차의 -노름을 최소화하는 방법을 제안했습니다. 기저 상태와 그 고유값을 구할 때 최소화할 수 있는 다른 양으로는 무엇이 있을까요?
정답:
오차의 -노름 대신 잔차 벡터를 사용하는 방법도 고려할 수 있습니다. 오차 벡터 자체를 고려하는 것이 유용한 경우도 있을 수 있습니다.
2. 고전 계산에서의 Krylov 방법
이 섹션에서는 Arnoldi 반복을 계산적으로 구현하여, 고유값 문제를 풀 때 Krylov 부분공간을 활용할 수 있도록 합니다. 먼저 소규모 예제에 적용한 뒤, 관심 행렬의 크기가 커질수록 계산 시간이 어떻게 변화하는지 살펴봅니다. 여기서 핵심 아이디어는, Krylov 공간을 펼치는 벡터들을 생성하는 과정이 총 계산 시간의 큰 부분을 차지한다는 점입니다. 메모리 요구량은 구체적인 Krylov 방법마다 다르지만, 메모리 제약이 전통적인 Krylov 방법의 사용을 제한할 수 있습니다.
2.1 간단한 소규모 예제
Krylov 부분공간을 생성하는 과정에서 부분공간 내 벡터들을 정규직교화해야 합니다. 이미 확립된 부분공간 벡터 vknown(정규화되지 않아도 됨)과 부분공간에 추가할 후보 벡터 vnext를 받아서, vnext를 vknown에 직교하도록 만들고 정규화하는 함수를 정의해 봅시다. 나아가 Krylov 부분공간에 이미 확립된 모든 벡터에 대해 이 과정을 단계적으로 수행하여 완전한 정규직교 집합을 보장하는 함수도 정의합니다.
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
이제 Krylov 부분공간을 반복적으로 확장하여, 해당 공간이 원래 행렬의 전체 공간을 포함할 때까지 키워나가는 함수를 정의합니다. 이를 통해 Krylov 부분공간 차원의 함수로서 Krylov 부분공간 방법으로 얻은 고유값이 정확한 값과 얼마나 잘 일치하는지 확인할 수 있습니다. 중요하게도, krylov_full_build 함수는 Krylov 벡터, 투영된 해밀토니안, 고유값, 그리고 소요 시간을 반환합니다.
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
이것을 아직은 작지만 손으로 계산하기에는 큰 행렬에 테스트해 봅시다.
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
마지막 단계(Krylov 공간이 원래 행렬의 전체 벡터 공간과 동일해지는 시점)에서 Krylov 방법의 고유값이 정확한 수치 대각화 결과와 완전히 일치하는지 확인함으로써 함수를 검증할 수 있습니다:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
성공적입니다. 물론, 진정으로 중요한 것은 Krylov 부분공간 차원의 함수로서 근사가 얼마나 좋은가입니다. 우리는 종종 바닥 상태 및 다른 최솟값 고유값(그리고 아래에서 설명할 대수적 이유들)을 찾는 데 관심이 있으므로, Krylov 부분공간 차원의 함수로서 최솟값 고유값의 추정치를 살펴봅시다. 이를 위한 코드는 다음과 같습니다.
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
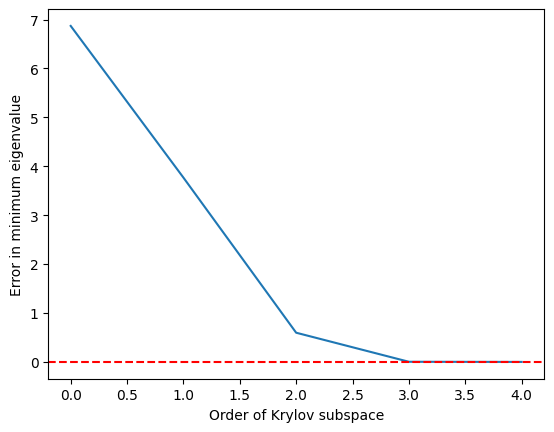
Krylov 부분공간이 로 성장하면 최솟값 고유값이 꽤 정확하게 도달되고, 에서는 완벽히 일치하는 것을 볼 수 있습니다.
2.2 행렬 차원에 따른 시간 스케일링
Krylov 방법이 정확한 수치 고유값 풀이 방법보다 유리할 수 있음을 다음과 같은 방식으로 확인해 봅시다:
- 무작위 행렬(희소하지 않고, KQD의 이상적인 적용 대상이 아님)을 생성합니다.
- 두 가지 방법으로 고유값을 구합니다: NumPy를 사용한 직접 계산과 Krylov 부분공간 사용.
- 고유값을 허용할 수 있을 만큼 정확하게 얻기 전까지의 기준을 설정합니다.
- 두 방법에 필요한 경과 시간을 비교합니다.
주의 사항: 아래에서 자세히 설명하겠지만, Krylov 양자 대각화는 행렬 표현이 희소하거나 적은 수의 교환 가능한 Pauli 연산자 그룹으로 나타낼 수 있는 연산자에 가장 잘 적용됩니다. 여기서 사용하는 무작위 행렬은 그 조건에 맞지 않습니다. 이 예제는 고전적인 Krylov 방법이 유용할 수 있는 규모를 탐색하는 데만 유용합니다. 또한, Krylov 방법을 사용할 때 다양한 크기의 Krylov 부분공간에 대해 고유값을 계산합니다. 바닥 상태 고유값에 대해 필요한 정확도를 처음으로 달성하는 최소 차원의 Krylov 부분공간에 대한 계산 시간을 기록합니다. 이는 필요한 차원을 평가하는 데 정확한 해를 사용하기 때문에 정확한 고유값 풀이 방법으로는 다루기 어려운 문제를 풀 때와는 다소 다릅니다.
무작위 행렬 집합을 생성하는 것부터 시작합니다.
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
이제 numpy를 사용하여 각 행렬을 직접 대각화합니다. 나중에 비교하기 위해 대각화에 필요한 시간을 계산합니다.
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
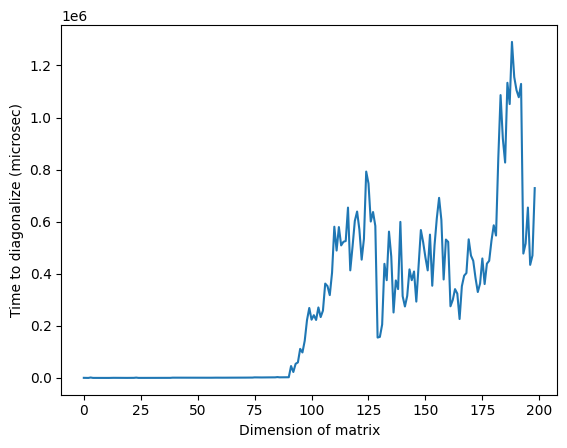
위 그래프에서 차원 약 125 부근의 이상하게 높은 시간은 행렬의 무작위성 또는 사용된 고전 프로세서의 구현 방식 때문일 수 있으며, 재현되지 않습니다. 코드를 다시 실행하면 이상 피크의 위치가 다른 다른 프로파일이 나타납니다.
이제 각 행렬에 대해 Krylov 부분공간을 단계적으로 구축하고 고유값을 계산합니다. 각 단계에서 최솟값 고유값이 지정된 절대 오차 범위 내에서 얻어졌는지 확인합니다. 지정된 오차 범위 내에서 고유값을 처음으로 제공하는 부분공간이 계산 시간을 기록할 부분공간입니다. 이 셀을 실행하는 데는 프로세서 속도에 따라 몇 분이 걸릴 수 있습니다. 평가를 건너뛰거나 대각화할 행렬의 최대 차원을 줄여도 됩니다. 미리 계산된 결과를 확인하는 것으로도 충분합니다.
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
두 방법으로 얻은 시간을 비교하여 시각화해 봅시다:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

이것이 실제 소요 시간이지만, 논의 목적상 인접한 몇 개의 점/행렬 차원에 대해 평균을 내어 이 곡선을 평활화해 봅시다. 아래에서 수행합니다:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

Krylov 부분공간을 구축하는 데 필요한 시간이 처음에는 numpy의 전체 대각화에 필요한 시간을 초과합니다. 하지만 행렬의 크기가 커질수록 Krylov 방법이 유리해집니다. 허용 오차를 낮춰도 이 현상은 마찬가지이지만, 더 큰 행렬 크기에서 이점이 나타나기 시작합니다. 이 점을 좀 더 자세히 살펴볼 필요가 있습니다.
수치 대각화의 시간 복잡도는 입니다(알고리즘에 따라 다소 차이가 있음). 개 벡터의 정규직교 기저를 생성하는 시간 복잡도도 입니다. 따라서 Krylov 방법의 이점은 정규직교 기저를 사용한다는 사실과는 관련이 없고, 관심 있는 고유값을 효과적으로 골라내는 특정 정규직교 기저를 사용한다는 점에 있습니다. 이미 이 강의의 첫 번째 섹션에서 증명의 개요를 통해 이를 확인했으며, 이것이 Krylov 방법의 수렴 보장에 핵심적입니다. 지금까지의 진행 상황을 정리해 봅시다:
- 매우 큰 행렬에 대해 Krylov 부분공간 방법은 전통적인 대각화 알고리즘보다 빠르게 필요한 허용 오차 내에서 근사 고유값을 산출할 수 있습니다.
- 그러한 매우 큰 행렬에 대해 Krylov 부분공간을 생성하는 것이 Krylov 부분공간 방법에서 가장 시간이 많이 걸리는 부분입니다.
- 따라서 Krylov 부분공간을 효율적으로 생성하는 방법은 매우 가치가 있습니다. 바로 이 지점에서 양자 컴퓨터가 등장합니다.
이해도 확인
아래 질문을 읽고 답을 생각해 본 후, 삼각형을 클릭하여 정답을 확인하세요.
위의 평활화된 대각화 시간 대 행렬 차원 그래프를 참조하세요.
(a) 이 그래프에 따르면 Krylov 방법이 더 빨라진 대략적인 행렬 차원은 어느 정도입니까?
(b) Krylov 방법이 더 빨라지는 해당 차원을 변화시킬 수 있는 계산의 요소는 무엇입니까?
정답:
(a) 계산을 다시 실행하면 결과가 달라질 수 있지만, Krylov 방법은 차원 약 80~85에서 더 빨라집니다. (b) 다양한 답이 가능합니다. 중요한 요소로는 요구하는 정밀도와 대각화할 행렬의 희소성이 있습니다.
3. 시간 진화를 통한 Krylov
지금까지 설명한 내용은 모두 고전적인 방식으로 수행할 수 있습니다. 그렇다면 양자 컴퓨터는 어떻게, 그리고 언제 활용할 수 있을까요? 행렬의 크기가 매우 클 경우, Krylov 방법은 긴 계산 시간과 많은 메모리를 필요로 할 수 있습니다. 를 에 곱하는 행렬 연산에 필요한 시간은 최악의 경우 으로 확장됩니다. 벡터에 희소 행렬을 곱하는 경우(고전적인 Krylov 방식 솔버의 전형적인 경우)도 시간 복잡도는 으로 확장됩니다. 이 연산은 부분 공간에 포함하려는 모든 벡터에 대해 수행됩니다. 부분 공간의 차원 은 보통 에 비해 크지 않으며, 종종 과 같이 확장됩니다. 따라서 모든 벡터를 생성하는 데는 최악의 경우 이 소요됩니다. 직교화와 같은 다른 단계도 있지만, 이것이 핵심적인 확장 기준입니다.
양자 컴퓨팅을 사용하면 문제의 어떤 속성이 시간 및 자원 확장을 결정하는지를 바꿀 수 있습니다. 행렬 크기 에 전반적으로 의존하는 방식 대신, 샷 수나 해밀토니안을 구성하는 비가환 Pauli 항의 수와 같은 요소가 중요해집니다. 이것이 어떻게 작동하는지 살펴보겠습니다.
3.1 시간 진화
양자 상태를 시간 진화시키는 연산자는 임을 상기하세요 (특히 양자 컴퓨팅에서는 를 표기에서 생략하는 것이 일반적입니다). 이러한 연산자의 지수 함수를 이해하고 구현하는 한 가지 방법은 테일러 급수 전개를 살펴보는 것입니다. 이 연산자를 초기 벡터 에 적용하면, 초기 상태에 의 거듭제곱이 점점 증가하며 곱해지는 항들의 합이 됩니다. 초기 추측 상태를 시간 진화시킴으로써 Krylov 부분 공간을 구성할 수 있을 것 같습니다!
주의할 점은 실제 양자 컴퓨터에서 시간 진화를 구현하는 것입니다. 해밀토니안의 많은 항들이 서로 가환이 아닙니다. 따라서 와 같은 일부 단순한 지수 연산자는 간단한 Circuit에 대응되지만, 일반적인 해밀토니안은 그렇지 않습니다. 또한 비가환 항들을 포함하므로, 숫자의 경우와 달리 지수 함수를 단순히 개별 항들의 곱으로 분해할 수 없습니다.
따라서 이는 간단한 문제가 아니지만, 양자 컴퓨팅에서 잘 연구된 과정입니다. 우리는 트로터화(trotterization)라는 과정을 통해 양자 컴퓨터에서 시간 진화를 수행하는데, 이 자체로도 풍부한 주제입니다[10]. 간략히 설명하자면, 시간 진화를 매우 작은 단계, 즉 크기 의 개의 단계로 나누면 항들의 비가환성의 영향을 최소화할 수 있습니다.
여기서 입니다.
고전적인 맥락에서 의 거듭제곱을 직접 사용해 생성한 차수 r의 Krylov 부분 공간을 "거듭제곱 Krylov 부분 공간"이라고 부르겠습니다.
이제 유니터리 시간 진화 연산자 를 사용하여 유사한 공간을 생성합니다. 이를 "유니터리 Krylov 공간" 이라고 부르겠습니다. 고전적으로 사용하는 거듭제곱 Krylov 부분 공간 은 가 유니터리 연산자가 아니기 때문에 양자 컴퓨터에서 직접 생성할 수 없습니다. 유니터리 Krylov 부분 공간을 사용하면 거듭제곱 Krylov 부분 공간과 유사한 수렴 보장을 제공할 수 있음이 알려져 있습니다. 구체적으로, 초기 상태 가 진정한 바닥 상태와 지수적으로 소멸하지 않는 겹침을 가지고, 고유값 사이에 충분한 간격이 있는 한 바닥 상태 오차는 효율적으로 수렴합니다. 보다 정확한 수렴 논의는 참고 문헌 [1]을 참조하세요.
여기서 의 거듭제곱은 서로 다른 시간 단계에 대응됩니다 (의 번째 거듭제곱은 시간 만큼 앞으로 진행하는 것입니다). 총 시간 만큼 시간 진화한 부분 공간의 원소를 로 표기합니다.
해밀토니안 H를 유니터리 Krylov 부분 공간 에 사영할 수 있습니다. 다시 말해, 기저에서 의 각 행렬 원소를 계산합니다. 이 사영된 행렬을 라고 부르겠습니다.
3.2 양자 컴퓨터에서의 구현 방법
의 행렬 원소는 기댓값 으로 주어지며, 이를 양자 컴퓨터를 사용해 추정할 수 있습니다. 는 서로 다른 Qubit에 대한 Pauli 연산자의 합으로 표현될 수 있으며, 모든 Pauli 연산자를 동시에 측정할 수는 없다는 점을 기억하세요. Pauli 항들을 가환 항들의 그룹으로 분류하면 한 번에 모두 측정할 수 있습니다. 하지만 모든 항을 커버하기 위해 여러 그룹이 필요할 수 있습니다. 따라서 항들을 분할할 수 있는 가환 그룹의 수 가 중요해집니다.
여기서 는 형태의 Pauli 문자열이거나 서로 가환인 Pauli 문자열들의 집합입니다. 를 이러한 측정 가능한 연산자들의 합으로 쓸 수 있다면, 의 행렬 원소에 대한 다음 식들을 Qiskit Runtime 기본 요소인 Estimator를 사용해 구현할 수 있습니다.
여기서 는 유니터리 Krylov 공간의 벡터이고, 는 선택된 시간 단계 의 배수입니다. 양자 컴퓨터에서 각 행렬 원소의 계산은 양자 상태 간의 겹침을 구할 수 있는 임의의 알고리즘으로 수행할 수 있습니다. 이 강의에서는 Hadamard 테스트에 초점을 맞추겠습니다. 의 차원이 이면, 부분 공간에 사영된 해밀토니안은 차원을 가집니다. 이 충분히 작을 경우(일반적으로 고유값 추정의 수렴을 위해 으로도 충분합니다), 사영된 해밀토니안 를 고전적으로 쉽게 대각화할 수 있습니다. 그러나 Krylov 공간 벡터들의 비직교성 때문에 를 직접 대각화할 수는 없습니다. 벡터들 간의 겹침을 측정하여 행렬 를 구성해야 합니다.
이를 통해 비직교 공간에서의 고유값 문제(일반화된 고유값 문제라고도 함)를 풀 수 있습니다.
그런 다음 이 일반화된 고유값 문제의 해를 통해 의 고유값과 고유 상태에 대한 추정치를 얻을 수 있습니다. 예를 들어, 바닥 상태 에너지의 추정치는 가장 작은 고유값 를 취하고, 대응하는 고유 벡터 로부터 바닥 상태를 구함으로써 얻습니다. 의 계수는 를 펼치는 서로 다른 벡터들의 기여도를 결정합니다.
일반화된 고유값 문제
왜 를 직접 대각화할 수 없을까요? 는 Krylov 기저의 기하 구조에 대한 정보(아주 특별한 경우를 제외하고는 비직교)를 담고 있기 때문에, 단독으로는 전체 해밀토니안의 사영을 올바르게 나타내지 못합니다. 따라서 의 고유값은 전체 해밀토니안의 고유값과 특별한 관계가 없으며 임의의 값이 될 수 있습니다. 전체 해밀토니안을 Krylov 공간에 사영한 근사 고유값과 고유 벡터를 구하려면 일반화된 고유값 문제를 풀어야 합니다.
이 그림은 서로 다른 양자 상태 간의 겹침을 계산하는 데 사용되는 수정된 Hadamard 테스트의 Circuit 표현을 보여줍니다. 각 행렬 원소 에 대해 상태 와 사이의 Hadamard 테스트가 수행됩니다. 이는 그림의 행렬 원소에 대한 색 구분과 대응하는 , 연산으로 강조되어 있습니다. 따라서 사영된 해밀토니안 의 모든 행렬 원소를 계산하려면 Krylov 공간 벡터들의 가능한 모든 조합에 대한 Hadamard 테스트 집합이 필요합니다. Hadamard 테스트 Circuit의 맨 위 와이어는 보조(ancilla) Qubit으로, X 또는 Y 기저에서 측정되며, 그 기댓값이 상태 간 겹침의 값을 결정합니다. 아래 와이어는 시스템 해밀토니안의 모든 Qubit을 나타냅니다. 연산은 보조 Qubit의 상태에 의해 제어되어 시스템 Qubit을 상태 로 준비하며 (도 마찬가지), 연산 는 시스템 해밀토니안의 Pauli 분해 를 나타냅니다. 양자 컴퓨터에서의 구현은 아래에서 보다 자세히 설명합니다.
4. 양자 컴퓨터에서의 Krylov 양자 대각화
이제 실제 양자 컴퓨터에서 Krylov 양자 대각화를 구현해 보겠습니다. 먼저 유용한 패키지들을 불러오겠습니다.
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
위에서 설명한 일반화 고유값 문제를 풀기 위해 아래의 함수를 정의합니다.
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
초기 벤치마킹 단계에서는 수렴 거동을 확인하기 위해 정확한 고전적 해를 알고 있는 것이 유용합니다. 아래 함수는 해밀토니안과 qubit 수를 인수로 받아 해밀토니안의 바닥 상태 에너지를 고전적으로 계산합니다.
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 단계 1: 문제를 양자 Circuit 및 연산자로 매핑하기
이제 해밀토니안을 정의하겠습니다. 위의 함수는 해밀토니안을 인수로 받아 고전적으로 바닥 상태만을 반환하는 반면, 여기서 정의하는 해밀토니안은 모든 에너지 고유 상태의 에너지 준위를 결정하며 파울리 연산자를 사용해 구성하여 양자 컴퓨터에서 구현할 수 있습니다.
공간 내에서 임의의 방향을 가질 수 있는 스핀 사슬인 "하이젠베르크 사슬(Heisenberg chain)"에 해당하는 해밀토니안을 선택합니다. 번째 스핀은 바로 인접한 이웃인 번째 및 번째 스핀의 영향을 받지만 더 멀리 떨어진 스핀의 영향은 받지 않는다고 가정합니다. 또한 스핀이 서로 다른 축 방향을 가리킬 때 스핀 간의 상호작용이 달라질 수 있는 가능성도 허용합니다. 이러한 비대칭성은 예를 들어 스핀이 내장된 결정 격자의 구조로 인해 발생하는 경우가 있습니다.
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
아래 코드는 해밀토니안을 단일 입자 상태로 제한하고, 스펙트럼 노름(spectral norm)을 사용하여 시간 간격 의 적절한 크기를 설정합니다. 시간 간격 dt에 대해 경험적 값을 선택합니다(해밀토니안 노름의 상한에 기반합니다). 참고 문헌 [9]에서는 충분히 작은 시간 간격이 임을 보였으며, 이 값을 과대 추정하는 것보다 과소 추정하는 것이 어느 정도까지는 더 유리하다는 점도 보여 주었습니다. 과대 추정할 경우 고에너지 상태의 기여가 Krylov 공간의 최적 상태마저 오염시킬 수 있기 때문입니다. 반면 를 너무 작게 선택하면 Krylov 기저 벡터들이 시간 간격마다 거의 달라지지 않으므로 Krylov 부분공간의 조건(conditioning)이 나빠집니다.
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
사용할 최대 Krylov 차원을 지정합니다(더 작은 차원에서의 수렴 여부도 확인할 예정입니다). 시간 진화에 사용할 트로터(Trotter) 단계 수도 지정합니다. 이 레슨에서는 단순히 5라는 작은 Krylov 차원을 선택합니다. 실제 응용의 관점에서는 매우 제한적이지만 이 예제에서는 충분합니다. 이후 레슨에서는 해밀토니안을 더 큰 부분공간으로 확장하고 투영할 수 있는 방법을 살펴볼 것입니다.
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
상태 준비
바닥 상태와 어느 정도 겹침(overlap)이 있는 기준 상태 를 선택합니다. 이 해밀토니안에 대해서는 중간 Qubit에 여기(excitation)가 있는 상태 를 기준 상태로 사용합니다.
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

시간 진화
Lie-Trotter 근사를 통해 주어진 해밀토니안에 의해 생성되는 시간 진화 연산자 를 구현할 수 있습니다. 단순성을 위해 시간 진화 Circuit에서 내장된 PauliEvolutionGate를 사용합니다. 일반적인 문법은 다음과 같습니다.
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
이 Circuit의 변형을 아래의 아다마르 테스트에서 사용하되, 시간 씩 앞으로 진행합니다.
아다마르 테스트
와 그람 행렬 의 행렬 원소를 모두 아다마르 테스트로 계산하려 한다는 점을 상기하세요. 먼저 의 구성에 초점을 맞추어 이 과정이 어떻게 동작하는지 살펴보겠습니다. 전체 과정은 아래에 도식으로 표현되어 있습니다. 색으로 표시된 상태 준비 블록 의 여러 레이어는 이 과정이 부분공간 내의 와 의 모든 조합에 대해 수행됨을 나타냅니다.
각 단계에서 시스템의 상태는 다음과 같습니다.
여기서 는 해밀토니안 분해의 파울리 항입니다(여러 교환 가능한 파울리 항의 선형 결합은 유니터리가 아니므로 여기서는 허용되지 않습니다 — 나중에 다른 구성을 통해 그룹화가 가능함을 보여드릴 것입니다). , 는 유니터리 Krylov 공간의 벡터 , 를 준비하는 제어 연산으로, 입니다. 이 Circuit에 및 측정을 적용하면 필요한 행렬 원소의 실수부와 허수부를 각각 계산할 수 있습니다.
위의 단계 4에서 시작하여 영번째 Qubit에 아다마르 Gate 를 적용합니다.
그런 다음 또는 를 측정합니다.
항등식 으로부터 도출됩니다. 마찬가지로 를 측정하면 다음을 얻습니다.
이전에 설정한 시간 진화에 이 단계들을 추가하여 다음과 같이 작성합니다.
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

트로터 Circuit에서 발생하는 깊이(depth) 문제에 대해 이미 경고한 바 있습니다. 이 조건에서 아다마르 테스트를 수행하면 기본 Gate로 분해한 후 Circuit이 훨씬 더 깊어질 수 있으며, 소자의 토폴로지(topology)를 고려하면 더욱 심해집니다. 따라서 양자 컴퓨터에서 시간을 사용하기 전에 Circuit의 2-Qubit 깊이를 확인하는 것이 좋습니다.
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
이 깊이의 Circuit은 현대 양자 컴퓨터에서 사용 가능한 결과를 반환할 수 없습니다. 와 를 구성하려면 더 나은 방법이 필요합니다. 바로 이것이 아래에서 소개하는 효율적인 아다마르 테스트가 필요한 이유입니다.
4. 2 Step 2. 타겟 하드웨어에 맞게 Circuit과 연산자 최적화
효율적인 Hadamard 테스트
깊은 Hadamard 테스트 Circuit을 최적화하기 위해 몇 가지 근사를 도입하고 모델 해밀토니안에 대한 가정을 활용할 수 있습니다. 예를 들어, 다음과 같은 Hadamard 테스트용 Circuit을 고려해 보겠습니다.
해밀토니안 하에서 의 고유값인 를 고전적으로 계산할 수 있다고 가정합니다. 이는 해밀토니안이 U(1) 대칭을 보존할 때 만족됩니다. 이것이 강한 가정처럼 보일 수 있지만, 해밀토니안의 작용에 영향을 받지 않는 진공 상태(이 경우 상태에 대응)가 존재한다고 안전하게 가정할 수 있는 경우가 많습니다. 예를 들어, 전자 수가 보존되는 안정적인 분자를 기술하는 화학 해밀토니안의 경우가 이에 해당합니다. 게이트 가 원하는 기준 상태 를 준비한다고 할 때, 예를 들어 화학의 HF 상태를 준비하기 위해 는 단일 qubit NOT의 곱이 되므로, controlled-는 CNOT의 곱이 됩니다. 그러면 위의 Circuit은 측정 직전에 다음 상태를 구현합니다.
여기서 Step 2에서 Step 3으로 가는 과정에서 고전적으로 시뮬레이션 가능한 위상 이동 을 사용하였습니다. 따라서 기댓값은 다음과 같습니다.
이러한 가정들을 활용하여 관심 있는 연산자의 기댓값을 더 적은 수의 controlled 연산으로 표현할 수 있게 되었습니다. 실제로 controlled 시간 진화가 아닌 controlled 상태 준비 만 구현하면 됩니다. 위와 같이 계산을 재구성하면 결과 Circuit의 깊이를 크게 줄일 수 있습니다.
파울리 연산자가 이제 Circuit 중간에 controlled 게이트가 아닌 Circuit 끝의 측정으로 나타나기 때문에, 위에서 주어진 분해 에서처럼 다른 교환 가능한 파울리 연산자들과 함께 측정할 수 있다는 추가적인 이점도 있습니다.
Trotter 분해를 이용한 시간 진화 연산자 분해
시간 진화 연산자를 정확하게 구현하는 대신, Trotter 분해를 사용하여 근사 구현을 할 수 있습니다. 특정 차수의 Trotter 분해를 여러 번 반복하면 근사에서 발생하는 오류를 더욱 줄일 수 있습니다. 다음에서는 고려하는 해밀토니안의 상호작용 그래프(최근접 이웃 상호작용만)에 가장 효율적인 방식으로 Trotter 구현을 직접 구성합니다. 실제로 매개변수화된 각도 를 가진 파울리 회전 , , 를 삽입하는데, 이는 의 근사 구현에 해당합니다. 파울리 회전의 정의와 구현하려는 시간 진화의 정의 차이로 인해, 의 시간 진화를 구현하려면 파라미터 를 사용해야 합니다. 또한 홀수 번 반복되는 Trotter 단계에서는 연산 순서를 뒤집는데, 이는 기능적으로 동일하지만 인접 연산을 단일 유니터리로 합성할 수 있게 해줍니다. 이를 통해 일반적인 PauliEvolutionGate() 기능을 사용할 때보다 훨씬 얕은 Circuit을 얻을 수 있습니다.
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
효율적인 Hadamard 테스트를 위해 초기 상태를 다시 준비합니다.
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

Hadamard 테스트를 통한 와 의 행렬 원소 계산을 위한 템플릿 Circuit
Hadamard 테스트에 사용되는 Circuit 간의 유일한 차이점은 시간 진화 연산자의 위상과 측정되는 관측량입니다. 따라서 시간 진화 연산자에 의존하는 게이트의 자리 표시자를 포함하는 Hadamard 테스트의 일반적인 Circuit을 나타내는 템플릿 Circuit을 준비할 수 있습니다.
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
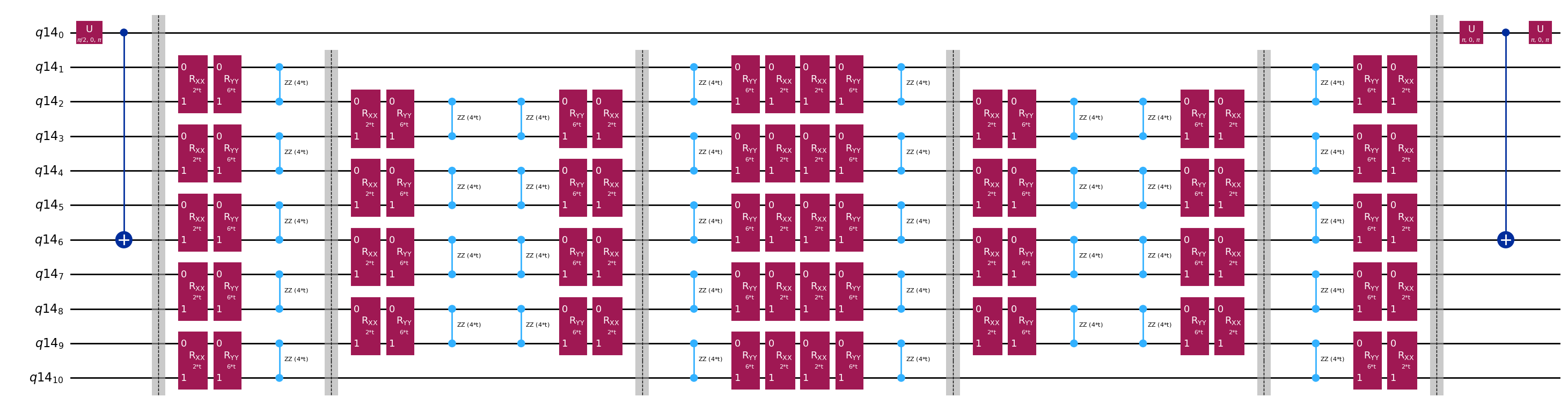
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
이 깊이는 원래 Hadamard 테스트에 비해 상당히 줄어든 것입니다. 이 깊이는 현대 양자 컴퓨터에서 다룰 수 있는 수준이지만, 여전히 꽤 높습니다. 유용한 결과를 얻으려면 최신 오류 완화 기술을 사용해야 합니다.
양자 Krylov 계산을 실행할 Backend를 선택하여 해당 양자 컴퓨터에서 실행할 수 있도록 Circuit을 Transpile합니다.
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
이제 Circuit과 연산자를 Transpile합니다.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

최적화 후 Transpile된 2-Qubit 깊이가 더욱 줄어들었습니다.
4.3 Step 3. Qiskit Runtime 프리미티브로 실행하기
이제 Estimator로 실행하기 위한 PUB을 생성합니다.
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
인 회로는 고전적으로 계산 가능합니다. 양자 컴퓨터를 사용하는 경우로 넘어가기 전에 먼저 이 계산을 수행합니다.
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
효율적인 Hadamard 테스트를 통해 게이트 깊이를 몇 자릿수 수준으로 줄일 수 있었지만, 그럼에도 여전히 최신 오류 경감 기법이 필요한 수준입니다. 아래에서는 사용되는 경감 기법의 속성을 지정합니다. 적용된 모든 방법이 중요하지만, 특히 확률적 오류 증폭(PEA)은 주목할 만합니다. 이 강력한 기법은 상당한 양자 오버헤드를 수반합니다. 여기서 수행하는 계산은 실제 양자 컴퓨터에서 실행하는 데 20분 이상 걸릴 수 있습니다. 아래 매개변수를 조정하여 정밀도와 그에 따른 오버헤드를 높이거나 낮출 수 있습니다. 아래의 기본 설정은 높은 충실도의 결과를 제공합니다.
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
마지막으로, Estimator를 사용해 와 에 대한 회로를 실행합니다.
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 단계 4. 후처리 및 결과 분석
양자 컴퓨터에서 얻은 결과물은 의 개별 행렬 원소와, 의 행렬 원소를 구성하는 가환 파울리 군입니다. 일반화 고유값 문제를 풀 수 있도록 행렬을 복원하려면 이 항들을 결합해야 합니다.
# Store the outputs as 'results'.
results = job.result()[0]
유효 해밀토니안 및 겹침 행렬 계산
먼저 비제어 시간 발전 동안 상태가 누적한 위상을 계산합니다.
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
Circuit 실행 결과를 얻은 후에는 데이터를 후처리하여 의 행렬 원소를 계산할 수 있습니다.
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
그리고 의 행렬 원소를 계산합니다.
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
마지막으로, 에 대한 일반화 고유값 문제를 풀 수 있습니다.
이를 통해 바닥 상태 에너지 의 추정값을 구할 수 있습니다.
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
print("The estimated ground state energy is: ", gnd_en_circ_est)
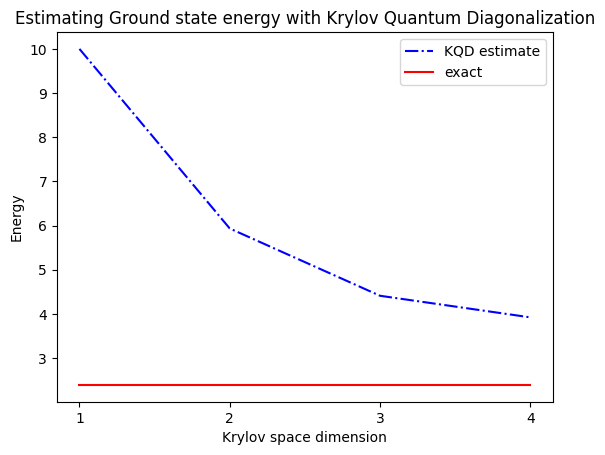
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
단일 입자 섹터의 경우, 해밀토니안에서 이 섹터의 바닥 상태를 고전적으로 효율적으로 계산할 수 있습니다.
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. 논의 및 확장
요약하자면, 우리는 기준 상태(reference state)에서 시작하여 서로 다른 시간 동안 상태를 발전시켜 유니터리 Krylov 부분 공간을 생성합니다. 그런 다음 해밀토니안을 해당 부분 공간에 투영합니다. 또한 부분 공간 벡터들의 겹침도 추정합니다. 마지막으로, 차원이 줄어든 일반화 고유값 문제를 고전적으로 풀어냅니다.
Krylov 기법을 고전적으로 사용할 때와 양자 역학적으로 사용할 때의 계산 비용을 결정하는 요인을 비교해 보겠습니다. 고전적 접근과 양자적 접근 사이에 모든 단계에 완벽한 대응이 있는 것은 아닙니다. 아래 표는 고려해야 할 다양한 단계들의 스케일링을 정리한 것입니다.
일반적으로 해밀토니안에는 동시에 측정할 수 없는 항들이 포함되어 있음을 기억하세요(서로 교환하지 않기 때문입니다). 우리는 해밀토니안의 항들을 동시에 측정 가능한 교환하는 파울리 연산자 그룹으로 분류하며, 서로 교환하지 않는 모든 항을 처리하기 위해 여러 그룹이 필요할 수 있습니다. 양자 컴퓨터에서 를 구성하려면 해밀토니안 내의 각 교환 파울리 문자열 그룹에 대해 별도의 측정이 필요하고, 각각에 대해 많은 샷이 필요합니다. 이를 서로 다른 시간 발전 인수의 가지 조합에 해당하는 개의 행렬 원소에 대해 수행해야 합니다. 이를 줄이는 방법이 있는 경우도 있지만, 이 대략적인 처리에서 소요 시간은 에 비례합니다. 의 원소 추정은 에 비례하며, 마지막으로 투영 공간에서의 일반화 고유값 문제를 고전적으로 푸는 것은 가 걸립니다.
양자 Krylov 대각화는 해밀토니안의 교환 파울리 그룹 수가 상대적으로 적은 경우에 유용할 수 있음을 알 수 있습니다. 이러한 스케일링 의존성은 Krylov 방법이 유용한 응용 분야와 그렇지 않을 분야를 시사합니다. 일부 해밀토니안은 큐비트에 매핑될 때 높은 복잡성을 가지며, 몇 개의 교환 그룹으로 쉽게 분리되지 않는 많은 비가환 파울리 문자열을 포함합니다. 이는 예를 들어 양자 화학 문제에서 흔히 나타납니다. 이러한 복잡성은 근사 기간 양자 컴퓨터에 두 가지 주요 어려움을 야기합니다:
- 의 각 원소 추정이 항의 수가 많아짐에 따라 계산 비용이 커집니다.
- 필요한 Trotter 회로가 지나치게 깊어집니다.
위의 두 문제는 양자 컴퓨터가 내결함성에 도달하면 덜 심각해지겠지만, 근사 기간에는 반드시 고려해야 합니다. 양자 화학보다 "단순한" 매핑을 가진 시스템이라도 해밀토니안에 비가환 항이 너무 많으면 동일한 장애를 겪을 수 있습니다. Krylov 방법은 해밀토니안을 비교적 적은 수의 교환 파울리 그룹으로 분리할 수 있고 를 Trotter 회로에서 쉽게 구현할 수 있는 경우에 가장 유용합니다. 이 두 조건은 물리학에서 관심 있는 많은 격자 모델에서 충족됩니다. KQD는 바닥 상태에 대한 정보가 거의 없을 때 특히 유용합니다. 이는 KQD가 본질적으로 수렴 보장을 가지며, 바닥 상태에 대한 정보가 부족하여 대안적 방법을 사용할 수 없는 상황에서도 적용 가능하기 때문입니다.
KQD는 강력한 도구이지만, 투영된 해밀토니안의 각 원소 추정과 Krylov 상태의 겹침 추정 등 프로토콜에서 시간이 많이 걸리는 부분은 개선의 여지가 있습니다. 대안적인 접근 방법으로 Krylov 방법을 샘플링 기반 방법과 결합하는 방식이 있으며, 이는 다음 강의의 주제입니다.
6. 부록
부록 I: 실수 시간 발전으로부터의 Krylov 부분 공간
유니터리 Krylov 공간은 다음과 같이 정의됩니다.
어떤 시간 간격 에 대해, 그 값은 나중에 결정합니다. 잠시 이 짝수라고 가정하고 로 정의합니다. 위의 Krylov 공간에 해밀토니안을 투영할 때, 이는 다음 Krylov 공간과 구별할 수 없음을 알 수 있습니다.
즉, 모든 시간 발전이 시간 간격만큼 뒤로 이동된 경우입니다. 구별할 수 없는 이유는 행렬 원소
가 발전 시간의 전체적인 이동에 불변하기 때문입니다. 시간 발전이 해밀토니안과 교환하므로 그렇습니다. 이 홀수인 경우에는 에 대한 분석을 사용할 수 있습니다.
이 Krylov 공간 어딘가에 낮은 에너지 상태가 반드시 존재함을 보이고자 합니다. 이를 위해 [3]의 정리 3.1에서 유도된 다음 결과를 활용합니다:
주장 1: 해밀토니안의 스펙트럼 범위(즉, 바닥 상태 에너지와 최대 에너지 사이)에 있는 에너지 에 대해 함수 가 존재하여...
- 로부터 떨어진 모든 값에 대해 , 즉 지수적으로 억제됨
- 는 에 대해 의 선형 결합
아래에 증명을 제시하지만, 완전한 엄밀한 논증을 이해하고 싶지 않다면 건너뛰어도 됩니다. 지금은 위 주장의 함의에 집중하겠습니다. 위의 성질 3에 의해, 앞서 이동된 Krylov 공간이 상태 를 포함함을 알 수 있습니다. 이것이 우리의 저에너지 상태입니다. 이를 확인하기 위해 를 에너지 고유 기저로 씁니다:
여기서 은 번째 에너지 고유 상태이고 는 초기 상태 에서의 진폭입니다. 이를 이용하면 는 다음과 같이 표현됩니다.
가 고유 상태 에 작용할 때 를 로 대체할 수 있다는 사실을 이용한 것입니다. 따라서 이 상태의 에너지 오차는
이 됩니다.
이를 더 이해하기 쉬운 상한으로 변환하기 위해, 분자의 합을 인 항과 인 항으로 분리합니다:
첫 번째 항을 로 상한 처리하면,
첫 번째 부등식은 합의 모든 에 대해 이기 때문이고, 두 번째는 분자의 합이 분모의 합의 부분 집합이기 때문입니다. 두 번째 항에서는 이므로 분모를 으로 하한 처리합니다. 모두 합치면
이 됩니다.
남은 부분을 단순화하기 위해, 이러한 모든 에 대해 의 정의에 의해 임을 주목합니다. 추가로 로 상한 처리하고 로 상한 처리하면
를 얻습니다.
이는 임의의 에 대해 성립하므로, 를 목표 오차와 같게 설정하면 위의 오차 상한은 Krylov 차원 에 대해 지수적으로 수렴합니다. 또한 이면 위 상한에서 항이 완전히 사라집니다.
논증을 완성하기 위해, 위의 결과는 Krylov 공간의 최저 에너지 상태가 아닌 특정 상태 의 에너지 오차임을 먼저 지적합니다. 그러나 (Rayleigh-Ritz) 변분 원리에 의해, Krylov 공간의 최저 에너지 상태의 에너지 오차는 Krylov 공간 내 임의의 상태의 에너지 오차로 상한 처리될 수 있으므로, 위 결과는 최저 에너지 상태, 즉 Krylov 양자 대각화 알고리즘의 출력에 대한 에너지 오차의 상한이기도 합니다.
위 분석과 유사한 분석을 수행하여 노이즈와 노트북에서 논의된 임계값 처리 절차를 추가로 고려할 수 있습니다. 이 분석에 대해서는 [2]와 [4]를 참조하세요.
부록 II: 주장 1의 증명
다음은 주로 [3]의 정리 3.1에서 유도됩니다: 이고 가 차수 이하의 잔차 다항식(0에서의 값이 1인 다항식)의 공간이라 하겠습니다. 다음의 해
는
이고, 이에 대응하는 최솟값은
입니다.
우리는 이를 복소 지수로 자연스럽게 표현할 수 있는 함수로 변환하고자 합니다. 복소 지수는 양자 Krylov 공간을 생성하는 실수 시간 발전에 해당하기 때문입니다. 이를 위해, 해밀토니안의 스펙트럼 범위 내 에너지를 범위의 수로 변환하는 다음 변환을 도입하는 것이 편리합니다:
여기서 는 를 만족하는 시간 간격입니다. 이고 가 에서 멀어질수록 가 증가함을 알 수 있습니다.
이제 다항식 에 , , 를 대입하여 다음 함수를 정의합니다:
여기서 는 바닥 상태 에너지입니다. 를 대입하면 가 차수 의 삼각 다항식, 즉 에 대해 의 선형 결합임을 알 수 있습니다. 더불어, 위의 정의에 의해 이고, 스펙트럼 범위 내에서 인 임의의 에 대해
가 성립합니다.
참고 문헌:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).