데이터 인코딩
소개 및 표기법
양자 알고리즘을 사용하려면 고전 데이터를 어떤 방식으로든 양자 Circuit에 가져와야 합니다. 이를 보통 데이터 인코딩이라고 하며, 데이터 로딩이라고도 부릅니다. 이전 단원에서 다룬 특징 매핑(feature mapping) 개념을 떠올려 보세요. 특징 매핑은 데이터의 특징을 한 공간에서 다른 공간으로 매핑하는 것입니다. 고전 데이터를 양자 컴퓨터로 단순히 옮기는 것도 일종의 매핑이며, 이를 특징 매핑이라고 부를 수 있습니다. 실제로 Qiskit에 내장된 특징 매핑(예: z_feature_map이나 zz_feature_map)은 대개 회전 레이어와 얽힘 레이어를 포함하여 상태를 힐베르트 공간의 여러 차원으로 확장합니다. 이 인코딩 과정은 양자 머신러닝 알고리즘의 핵심 부분으로, 알고리즘의 계산 능력에 직접적인 영향을 미칩니다.
아래의 일부 인코딩 기법은 고전적으로도 효율적으로 시뮬레이션할 수 있습니다. 이는 특히 곱 상태(product state)를 생성하는 인코딩 방법(즉, Qubit를 얽히게 하지 않는 방법)에서 쉽게 확인할 수 있습니다. 그리고 양자 유용성(quantum utility)은 데이터셋의 양자적 복잡성이 인코딩 방법과 잘 맞아떨어질 때 가장 발현될 가능성이 높습니다. 따라서 직접 인코딩 Circuit을 작성해야 하는 경우가 많을 것입니다. 여기서는 다양한 인코딩 전략을 비교·대조하고 어떤 것이 가능한지 살펴볼 수 있도록 폭넓은 전략을 소개합니다. 인코딩 기법의 유용성에 대해 몇 가지 일반적인 진술을 할 수 있습니다. 예를 들어, 완전 얽힘 방식의 efficient_su2(아래 참고)는 곱 상태를 생성하는 방법(z_feature_map 등)보다 데이터의 양자적 특징을 포착할 가능성이 훨씬 높습니다. 그렇다고 efficient_su2가 충분하거나 여러분의 데이터셋에 충분히 잘 맞아 양자 속도 향상을 보장한다는 의미는 아닙니다. 이는 모델링하거나 분류하려는 데이터 구조를 신중하게 고려해야 합니다. 또한 Circuit 깊이와의 균형도 중요합니다. Circuit의 Qubit를 완전히 얽히게 하는 특징 매핑은 매우 깊은 Circuit을 만드는 경우가 많아, 현재 양자 컴퓨터에서 유용한 결과를 얻기 어려울 수 있습니다.
표기법
데이터셋은 개의 데이터 벡터 집합입니다: . 각 벡터는 차원, 즉 입니다. 이는 복소 데이터 특징으로도 확장할 수 있습니다. 이 단원에서는 전체 집합 과 특정 원소 등의 표기법을 가끔 사용합니다. 하지만 대부분의 경우 데이터셋에서 한 번에 하나의 벡터를 불러오는 것을 다루며, 개의 특징을 가진 단일 벡터를 단순히 로 표기하는 경우가 많습니다.
또한 는 데이터 벡터 의 특징 매핑 를 나타내는 데 사용하는 것이 일반적입니다. 양자 컴퓨팅에서는 특히 라는 표기를 사용하는 경우가 많은데, 이는 이러한 연산의 유니타리 특성을 강조하는 표기법입니다. 두 표기 모두 올바르게 사용할 수 있으며, 둘 다 특징 매핑입니다. 이 과정에서는 다음과 같이 사용합니다:
- 머신러닝에서 특징 매핑을 일반적으로 논의할 때는 를,
- 특징 매핑의 Circuit 구현을 논의할 때는 를 사용합니다.
정규화와 정보 손실
고전 머신러닝에서 훈련 데이터의 특징은 종종 "정규화"되거나 재조정되며, 이는 대개 모델 성능을 향상시킵니다. 일반적인 방법 중 하나는 최솟값-최댓값 정규화(min-max normalization) 또는 표준화(standardization)를 사용하는 것입니다. 최솟값-최댓값 정규화에서는 데이터 행렬 의 특징 열(예: 특징 )이 다음과 같이 정규화됩니다:
여기서 min과 max는 데이터셋 의 개 데이터 벡터에 걸쳐 특징 의 최솟값과 최댓값을 의미합니다. 이렇게 하면 모든 특징 값이 단위 구간 안에 들어오게 됩니다: 모든 , 에 대해 .
정규화는 양자역학과 양자 컴퓨팅에서도 근본적인 개념이지만, 최솟값-최댓값 정규화와는 약간 다릅니다. 양자역학에서의 정규화는 상태 벡터 의 길이(양자 컴퓨팅 맥락에서는 2-노름)가 1이어야 한다는 조건을 의미합니다: . 이는 측정 확률의 합이 1임을 보장합니다. 상태는 2-노름으로 나누어 정규화됩니다. 즉, 다음과 같이 재조정합니다:
양자 컴퓨팅과 양자역학에서 이는 사람들이 데이터에 인위적으로 부과하는 정규화가 아니라, 양자 상태의 근본적인 성질입니다. 인코딩 방식에 따라 이 제약이 데이터 재조정 방식에 영향을 줄 수 있습니다. 예를 들어, 진폭 인코딩(아래 참고)에서는 양자역학의 요구에 따라 데이터 벡터가 로 정규화되며, 이는 인코딩되는 데이터의 스케일링에 영향을 미칩니다. 위상 인코딩에서는 특징 값을 로 재조정하도록 권장하는데, 이는 qubit 위상 각도로 인코딩할 때 발생하는 모듈로 효과로 인한 정보 손실을 방지하기 위해서입니다[1,2].
인코딩 방법
다음 몇 개의 절에서는 개의 데이터 벡터로 구성된 소규모 고전 데이터셋 예시 를 참고합니다. 각 벡터는 개의 특징을 가집니다:
위에서 소개한 표기법으로 예를 들면, 집합 의 번째 데이터 벡터의 번째 특징은 라고 할 수 있습니다.
기저 인코딩
기저 인코딩은 고전 -비트 문자열을 -Qubit 시스템의 계산 기저 상태로 인코딩합니다. 예를 들어 을 생각해봅시다. 이는 -비트 문자열 로 표현할 수 있으며, -Qubit 시스템에서 양자 상태 로 나타냅니다. 일반적으로 -비트 문자열에 대해: 이면, 대응하는 -Qubit 상태는 이며, 에 대해 입니다. 이는 단일 특징에 대한 것임을 유의하세요.
양자 컴퓨팅에서 기저 인코딩은 각 고전 비트를 별도의 Qubit로 나타내며, 데이터의 이진 표현을 계산 기저의 양자 상태로 직접 매핑합니다. 여러 특징을 인코딩해야 할 경우, 각 특징을 먼저 이진 형식으로 변환한 다음 별개의 qubit 그룹에 할당합니다. 각 특징마다 하나의 그룹이 배정되며, 각 Qubit는 해당 특징의 이진 표현에서 하나의 비트를 반영합니다.
예시로 벡터 (5, 7, 0)을 인코딩해 봅시다.
모든 특징이 4비트로 저장된다고 가정합니다(필요한 것보다 많지만, 십진수 한 자리 정수를 모두 표현하기에 충분합니다):
5 → binary 0101
7 → binary 0111
0 → binary 0000
이 비트 문자열들은 세 개의 4-Qubit 집합에 할당되므로, 전체 12-Qubit 기저 상태는:
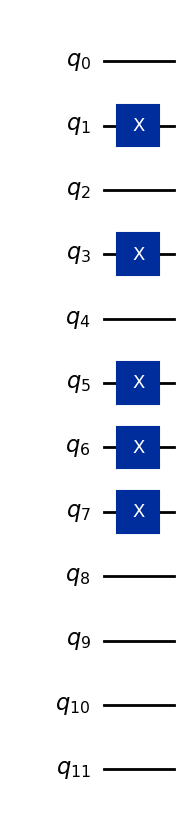
여기서 처음 네 Qubit는 첫 번째 특징을, 다음 네 Qubit는 두 번째 특징을, 마지막 네 Qubit는 세 번째 특징을 나타냅니다. 아래 코드는 데이터 벡터 (5,7,0)을 양자 상태로 변환하며, 다른 한 자리 특징에도 일반화하여 적용할 수 있습니다.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
이해도 확인
아래 질문을 읽고 답을 생각한 후, 삼각형을 클릭하여 정답을 확인하세요.
예시 데이터셋 의 첫 번째 벡터:
를 기저 인코딩을 사용하여 인코딩하는 코드를 작성하세요.
정답:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
진폭 인코딩
진폭 인코딩은 데이터를 양자 상태의 진폭(amplitude)으로 인코딩합니다. 정규화된 고전적인 차원 데이터 벡터 를 -Qubit 양자 상태 의 진폭으로 표현합니다:
여기서 은 앞서와 동일한 데이터 벡터의 차원, 는 의 번째 원소, 은 번째 계산 기저 상태입니다. 는 인코딩할 데이터로부터 결정되는 정규화 상수이며, 이는 양자역학에서 부과되는 정규화 조건입니다:
일반적으로 이 조건은 모든 데이터 벡터에 걸쳐 각 특성에 적용되는 최솟값/최댓값 정규화와는 다른 조건입니다. 이를 어떻게 처리할지는 풀고자 하는 문제에 따라 달라지지만, 위의 양자역학적 정규화 조건을 피할 방법은 없습니다.
진폭 인코딩에서는 데이터 벡터의 각 특성이 서로 다른 양자 상태의 진폭으로 저장됩니다. -Qubit 시스템은 개의 진폭을 제공하므로, 개의 특성을 진폭 인코딩하려면 개의 Qubit이 필요합니다.
예시로, 예제 데이터셋 의 첫 번째 벡터인 를 진폭 인코딩으로 인코딩해 보겠습니다. 결과 벡터를 정규화하면 다음과 같습니다:
그리고 이에 대응하는 2-Qubit 양자 상태는 다음과 같습니다:
위 예시에서 벡터의 특성 수 은 2의 거듭제곱이 아닙니다. 이 2의 거듭제곱이 아닌 경우, 을 만족하는 qubit 수 을 선택하고 진폭 벡터를 정보가 없는 상수(여기서는 0)로 패딩합니다.
기저 인코딩과 마찬가지로, 데이터셋을 인코딩할 상태를 계산한 후 Qiskit에서 initialize 함수를 사용해 해당 상태를 준비할 수 있습니다:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

진폭 인코딩의 장점은 앞서 언급한 것처럼 인코딩에 개의 Qubit만 필요하다는 점입니다. 그러나 후속 알고리즘이 양자 상태의 진폭 위에서 동작해야 하며, 양자 상태를 준비하고 측정하는 방법이 효율적이지 않은 경향이 있습니다.
이해도 확인
아래 질문을 읽고 답을 생각해 본 후, 삼각형을 클릭하여 해답을 확인하세요.
다음 벡터(예제 데이터셋의 두 벡터를 합친 것)를 진폭 인코딩으로 표현할 때의 정규화된 상태를 써보세요:
정답:
6개의 숫자를 인코딩하려면 진폭으로 인코딩할 수 있는 상태가 최소 6개 이상 필요합니다. 이를 위해 3개의 Qubit이 필요합니다. 미지의 정규화 인수 를 사용하면 다음과 같이 쓸 수 있습니다:
주목하세요.
따라서 최종 결과는,
같은 데이터 벡터 에 대해 진폭 인코딩으로 데이터 특성을 로드하는 Circuit을 생성하는 코드를 작성하세요.
정답:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

매우 큰 데이터 벡터를 다루어야 할 수도 있습니다. 다음 벡터를 고려하세요:
정규화를 자동화하고 진폭 인코딩을 위한 양자 Circuit을 생성하는 코드를 작성하세요.
정답:
정답은 여러 가지가 있을 수 있습니다. 아래는 중간 단계를 출력하는 코드 예시입니다:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
기저 인코딩에 비해 진폭 인코딩이 가지는 장점이 있다고 생각하시나요? 있다면 설명해 보세요.
정답:
여러 가지 답이 있을 수 있습니다. 한 가지 답은, 기저 상태의 순서가 고정되어 있으므로 이 진폭 인코딩은 인코딩된 숫자들의 순서를 보존한다는 점입니다. 또한 대부분의 경우 더 조밀하게 인코딩됩니다.
진폭 인코딩의 장점은 차원(-특성) 데이터 벡터 를 인코딩하는 데 개의 Qubit만 필요하다는 것입니다. 그러나 진폭 인코딩은 일반적으로 비효율적인 절차로, CNOT Gate 수가 지수적으로 증가하는 임의 상태 준비가 필요합니다. 달리 말하면, 상태 준비의 런타임 복잡도는 차원 수 기준으로 (여기서 , 은 qubit 수)의 다항 복잡도를 가집니다. 진폭 인코딩은 "공간에서의 지수적 절약을 시간에서의 지수적 증가라는 대가로 제공합니다"[3]. 단, 특정 경우에는 런타임을 으로 개선할 수 있습니다[4]. 종단 간 양자 속도 향상을 위해서는 데이터 로딩 런타임 복잡도를 함께 고려해야 합니다.
각도 인코딩
각도 인코딩은 양자 지지 벡터 머신(QSVM), 변분 양자 회로(VQC) 등 Pauli 피처 맵을 사용하는 많은 QML 모델에서 활용됩니다. 각도 인코딩은 아래에서 소개할 위상 인코딩 및 밀집 각도 인코딩과 밀접하게 관련되어 있습니다. 여기서는 "각도 인코딩"이라는 용어를 방향의 회전, 즉 Gate 또는 Gate 등을 사용하여 축에서 벗어나는 회전을 의미하는 것으로 사용하겠습니다[1,3]. 실제로는 임의의 회전 또는 회전의 조합으로 데이터를 인코딩할 수 있습니다. 그러나 는 문헌에서 널리 사용되므로 여기서는 이를 중심으로 설명합니다.
단일 Qubit에 적용할 경우, 각도 인코딩은 데이터 값에 비례하는 Y축 회전을 부여합니다. 데이터셋의 번째 데이터 벡터에서 단일 (번째) 피처 를 인코딩하는 과정을 살펴보겠습니다.
또는 Gate를 사용하여 각도 인코딩을 수행할 수도 있습니다. 다만 이 경우 인코딩된 상태는 에 비해 복소수 상대 위상을 갖게 됩니다.
각도 인코딩은 앞서 설명한 두 방법과 여러 면에서 다릅니다. 각도 인코딩의 특징은 다음과 같습니다.
- 각 피처 값이 대응하는 Qubit에 매핑되어 , Qubit들은 곱 상태(product state)로 남습니다.
- 데이터 포인트의 전체 피처 집합이 아닌 하나의 수치 값을 한 번에 인코딩합니다.
- 개의 데이터 피처를 인코딩하는 데 개의 Qubit이 필요하며, 입니다. 보통은 등호가 성립합니다. 이 가능한 경우는 다음 몇 섹션에서 살펴보겠습니다.
- 결과 Circuit은 일정한 깊이를 가집니다(보통 트랜스파일 전 깊이는 1입니다).
일정한 깊이의 양자 Circuit은 현재 양자 하드웨어에서 구현하기 특히 유리합니다. 로 데이터를 인코딩하는 방식(특히 Y축 각도 인코딩 선택)의 추가적인 특징은 특정 응용에서 유용할 수 있는 실수값 양자 상태를 생성한다는 점입니다. Y축 회전의 경우, 데이터는 실수값 각도 에 대한 Y축 회전 Gate 로 매핑됩니다(Qiskit RYGate). 위상 인코딩(아래 참조)과 마찬가지로, 정보 손실과 기타 원하지 않는 효과를 방지하기 위해 가 되도록 데이터를 재조정할 것을 권장합니다.
아래 Qiskit 코드는 단일 Qubit을 초기 상태 에서 데이터 값 를 인코딩하도록 회전시킵니다.
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
상태 벡터의 동작을 시각화하는 함수를 정의해 보겠습니다. 함수 정의의 세부 사항은 중요하지 않지만, 상태 벡터와 그 변화를 시각화할 수 있는 능력이 중요합니다.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

위 예시는 단일 데이터 벡터의 단일 피처에 해당합니다. 개의 피처를 개의 Qubit의 회전 각도로 인코딩할 때, 예를 들어 번째 데이터 벡터 에 대해 인코딩된 곱 상태는 다음과 같습니다.
이는 다음과 동일합니다.
이해도 확인
아래 질문을 읽고 답을 생각해 본 후, 삼각형을 클릭하여 정답을 확인하세요.
위에서 설명한 각도 인코딩을 사용하여 데이터 벡터 를 인코딩하세요.
정답:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

위에서 설명한 각도 인코딩을 사용하여 5개의 피처를 인코딩하려면 몇 개의 Qubit이 필요한가요?
정답: 5
위상 인코딩
위상 인코딩은 위에서 설명한 각도 인코딩과 매우 유사합니다. Qubit의 위상 각도는 + 축으로부터 축을 중심으로 한 실수값 각도 입니다. 데이터는 위상 회전 로 매핑되며, 여기서 입니다(자세한 내용은 Qiskit PhaseGate 참조). 정보 손실과 기타 원하지 않는 효과를 방지하기 위해 가 되도록 데이터를 재조정할 것을 권장합니다[1,2].
Qubit은 보통 위상 회전 연산자의 고유 상태인 상태로 초기화됩니다. 따라서 위상 인코딩을 구현하려면 먼저 qubit 상태를 회전시켜야 합니다. 그러므로 Hadamard Gate로 상태를 초기화하는 것이 자연스럽습니다: . 단일 Qubit에서의 위상 인코딩은 데이터 값에 비례하는 상대 위상을 부여하는 것을 의미합니다.
위상 인코딩 절차는 각 피처 값을 대응하는 Qubit의 위상에 매핑합니다: . 전체적으로 위상 인코딩은 Hadamard 레이어를 포함하여 Circuit 깊이가 2이므로 효율적인 인코딩 방식입니다. 위상 인코딩된 다중 qubit 상태(개의 피처에 대해 개의 qubit)는 곱 상태입니다.
아래 Qiskit 코드는 먼저 Hadamard Gate로 단일 Qubit의 초기 상태를 준비한 다음, 위상 Gate를 사용하여 데이터 피처 를 인코딩합니다.
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

앞서 정의한 plot_Nstates 함수를 사용하여 방향의 회전을 시각화할 수 있습니다.
plot_Nstates(states, axis=None, plot_trace_points=True)

Bloch 구 플롯은 일 때의 Z축 회전 를 보여줍니다. 연한 초록색 화살표가 최종 상태를 나타냅니다.
위상 인코딩은 및 피처 맵, 일반 Pauli 피처 맵 등 많은 양자 피처 맵에서 사용됩니다.
이해도 확인
아래 질문을 읽고 답을 생각해 본 후, 삼각형을 클릭하여 정답을 확인하세요.
위에서 설명한 위상 인코딩을 사용하여 8개의 피처를 저장하려면 몇 개의 Qubit이 필요한가요?
정답: 8
위상 인코딩을 사용하여 벡터 를 인코딩하는 코드를 작성하세요.
정답:
정답은 여러 가지가 있을 수 있습니다. 다음은 하나의 예시입니다.
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

밀집 각도 인코딩
밀집 각도 인코딩(DAE)은 각도 인코딩과 위상 인코딩을 결합한 방식입니다. DAE를 사용하면 단일 Qubit에 두 개의 피처 값을 인코딩할 수 있습니다. 하나는 Y축 회전 각도로, 다른 하나는 축 회전 각도로 인코딩합니다: . 두 개의 피처를 다음과 같이 인코딩합니다.
하나의 Qubit에 두 개의 데이터 피처를 인코딩함으로써 필요한 qubit 수를 줄일 수 있습니다. 더 많은 피처로 확장하면, 데이터 벡터 을 다음과 같이 인코딩할 수 있습니다.
DAE는 여기서 사용된 삼각함수 대신 두 피처의 임의 함수로 일반화할 수 있습니다. 이를 일반 qubit 인코딩이라고 합니다[7].
DAE의 예시로, 아래 코드는 피처 , 의 인코딩 및 시각화를 보여줍니다.
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

이해도 확인
아래 질문을 읽고 답을 생각해 본 후, 삼각형을 클릭하여 정답을 확인하세요.
위의 설명에 따르면, 밀집 인코딩을 사용하여 6개의 피처를 인코딩하는 데 몇 개의 Qubit이 필요한가요?
정답: 3
밀집 각도 인코딩을 사용하여 벡터 를 불러오는 코드를 작성하세요.
정답:
인코딩 방식에서 사용되지 않는 단일 파라미터 문제를 피하기 위해 목록에 "0"을 패딩했습니다.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

내장 특성 맵을 이용한 인코딩
임의의 지점에서의 인코딩
각도 인코딩, 위상 인코딩, 밀집 인코딩은 각 Qubit에 하나의 특성을 인코딩하는(또는 Qubit당 두 개의 특성을 인코딩하는) 곱 상태(product state)를 준비했습니다. 이는 기저 인코딩 및 진폭 인코딩과는 다릅니다. 기저 인코딩과 진폭 인코딩은 얽힘 상태를 활용하므로, 데이터 특성과 qubit 사이에 1:1 대응이 없습니다. 예를 들어 진폭 인코딩에서는 하나의 특성이 상태 의 진폭이고 또 다른 특성이 의 진폭일 수 있습니다. 일반적으로 곱 상태로 인코딩하는 방법은 더 얕은 Circuit을 만들며 Qubit당 1~2개의 특성을 저장할 수 있습니다. 얽힘을 이용하고 특성을 Qubit이 아닌 상태에 연결하는 방법은 더 깊은 Circuit을 만들지만, 평균적으로 Qubit당 더 많은 특성을 저장할 수 있습니다.
하지만 인코딩이 반드시 완전히 곱 상태이거나 진폭 인코딩처럼 완전히 얽힘 상태일 필요는 없습니다. 실제로 Qiskit에 내장된 많은 인코딩 방식은 처음에만 인코딩하는 것이 아니라 얽힘 레이어 전후 모두에서 인코딩할 수 있습니다. 이를 "데이터 재업로딩(data reuploading)"이라고 합니다. 관련 연구는 참고문헌 [5]와 [6]을 참조하세요.
이 절에서는 내장된 인코딩 방식 몇 가지를 사용하고 시각화합니다. 이 절의 모든 방법은 개의 Qubit에 있는 개의 매개변수화된 Gate의 회전으로 개의 특성을 인코딩합니다. 여기서 입니다. 주어진 qubit 수에 대해 데이터 로딩을 최대화하는 것만이 유일한 고려 사항은 아닙니다. 많은 경우, Circuit 깊이가 qubit 수보다 훨씬 더 중요한 고려 사항이 될 수 있습니다.
Efficient SU2
얽힘을 이용한 인코딩의 일반적이고 유용한 예시가 바로 Qiskit의 efficient_su2 Circuit입니다. 인상적이게도, 이 Circuit은 예를 들어 단 2개의 Qubit에 8개의 특성을 인코딩할 수 있습니다. 이를 확인하고, 어떻게 가능한지 이해해 보겠습니다.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

상태를 표기할 때, 최하위 유효 Qubit이 가장 오른쪽에 오는 Qiskit 규칙인 또는 을 사용합니다. 이러한 상태는 매우 빠르게 복잡해질 수 있으며, 이 드문 예시가 왜 이런 상태들이 명시적으로 쓰이지 않는지를 설명하는 데 도움이 될 것입니다.
시스템은 상태에서 시작합니다. 첫 번째 배리어(이라고 표시)까지 우리의 상태는 다음과 같습니다:
이는 우리가 이미 살펴본 밀집 인코딩입니다. CNOT Gate 이후, 두 번째 배리어()에서 상태는 다음과 같습니다.
이제 마지막 단일 qubit 회전을 적용하고 같은 상태끼리 모아 최종 결과를 얻습니다:
이 식은 아마도 분석하기에 너무 복잡할 것입니다. 대신, 상태에 몇 개의 매개변수를 로딩했는지 생각해 보세요: 바로 여덟 개입니다. 그러나 계산 기저 상태는 단 네 개뿐입니다. 언뜻 보면 의미 있는 것보다 더 많은 매개변수를 로딩한 것처럼 보일 수 있습니다. 최종 상태는 으로 쓸 수 있기 때문입니다. 그러나 각 계수가 복소수임에 주목하세요! 이렇게 쓰면:
우리가 실제로 여덟 개의 특성을 인코딩할 수 있는 여덟 개의 매개변수를 상태에 가지고 있음을 알 수 있습니다.
Qubit 수를 늘리고 얽힘 레이어와 회전 레이어의 반복 횟수를 늘림으로써 훨씬 더 많은 데이터를 인코딩할 수 있습니다. 파동 함수를 명시적으로 적어 내려가는 것은 금방 다루기 어려워집니다. 그러나 인코딩이 실제로 작동하는 것은 여전히 확인할 수 있습니다.
다음은 12개의 특성을 가진 데이터 벡터 를, 3-Qubit efficient_su2 Circuit을 사용하여 각 매개변수화된 Gate가 서로 다른 특성을 인코딩하도록 인코딩하는 예시입니다.
이 데이터 벡터에서 특성은 특정 순서로 나열되어 있습니다. 독립적으로 보면 이 순서대로 또는 역순으로 인코딩해도 무방합니다. 중요한 것은 순서를 추적하고 일관성을 유지하는 것입니다. Circuit 다이어그램에서 efficient_su2는 특정 인코딩 순서를 가정합니다. 구체적으로 qubit 0부터 qubit 2까지 매개변수화된 Gate의 첫 번째 레이어를 채운 후 다음 레이어로 이동합니다. 인코딩 Circuit이 지정되기 전에는 데이터 특성을 qubit 순서에 따라 사전에 정렬할 수 없으므로, 이는 리틀 엔디안 표기법과 일치하거나 불일치하는 것이 아닙니다.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Qubit 수를 늘리는 대신 얽힘 레이어와 회전 레이어의 반복 횟수를 늘리는 방법을 선택할 수도 있습니다. 하지만 반복 횟수가 유용하게 작동하는 데는 한계가 있습니다. 앞서 언급했듯이, 트레이드오프가 존재합니다. Qubit 수가 많거나 얽힘 레이어와 회전 레이어 반복이 많은 Circuit은 더 많은 매개변수를 저장할 수 있지만, 더 큰 Circuit 깊이를 수반합니다. 내장된 특성 맵들의 깊이는 아래에서 다시 살펴보겠습니다. 다음에 소개되는 Qiskit에 내장된 인코딩 방법들에는 이름에 "특성 맵(feature map)"이 포함되어 있습니다. 데이터를 양자 Circuit에 인코딩하는 것이 곧 특성 매핑이라는 점을 다시 강조합니다. 데이터를 새로운 공간, 즉 관련된 Qubit의 힐베르트 공간으로 가져가기 때문입니다. 원래 특성 공간의 차원과 힐베르트 공간 차원 사이의 관계는 인코딩에 사용하는 Circuit에 따라 달라집니다.
feature map
feature map(ZFM)은 위상 인코딩의 자연스러운 확장으로 해석할 수 있습니다. ZFM은 단일 qubit Gate 층이 교대로 반복되는 구조, 즉 Hadamard Gate 층과 위상 Gate 층으로 이루어져 있습니다. 데이터 벡터 가 개의 특성을 가진다고 할 때, feature mapping을 수행하는 양자 Circuit은 초기 상태에 작용하는 유니터리 연산자로 표현됩니다:
여기서 은 -Qubit 기저 상태입니다. 이 표기법은 참고문헌 [4] Havlicek et al.과의 일관성을 위해 사용되었습니다. 데이터 특성 는 대응하는 Qubit에 일대일로 매핑됩니다. 예를 들어 데이터 벡터에 8개의 특성이 있다면 8개의 Qubit을 사용합니다. ZFM Circuit은 Hadamard Gate 층과 위상 Gate 층으로 구성된 서브회로를 번 반복한 구조입니다. Hadamard 층은 -Qubit 레지스터의 모든 Qubit에 Hadamard Gate가 동시에 작용하는 것, 즉 을 의미합니다. 위상 Gate 층도 마찬가지로 번째 Qubit에 가 작용합니다. 각 Gate는 특성 하나를 인수로 받지만, 위상 Gate 층 전체()는 데이터 벡터의 함수입니다. 단일 반복에서 ZFM Circuit 유니터리 전체는 다음과 같습니다:
이 유니터리를 번 반복하면 다음과 같습니다:
데이터 특성 는 번의 모든 반복에서 동일한 방식으로 위상 Gate에 매핑됩니다. ZFM feature map 상태는 곱 상태(product state)이며, 고전적 시뮬레이션이 효율적으로 가능합니다[4].
간단한 예시로, 2-Qubit ZFM Circuit을 Qiskit으로 작성하고 그려 보면 단순한 Circuit 구조를 확인할 수 있습니다. 이 예시에서는 단일 반복 을 사용하고, 데이터 벡터는 입니다. 이는 Python 벡터의 표준 순서로 작성된 것으로, 번째 원소는 입니다. 이 번째 특성을 번째 Qubit에 인코딩할 수도 있고 번째 Qubit에 인코딩할 수도 있습니다. 그러나 feature map마다 각 Qubit에 인코딩하는 특성 수가 다르기 때문에, 특성 순서와 qubit 순서 사이에 항상 일대일 매핑이 성립하지는 않습니다. 중요한 것은 각 특성이 어디에 인코딩되는지를 파악하는 것입니다. feature map에 파라미터 목록을 제공하면, 목록의 0번째 특성을 파라미터화된 Gate가 있는 최하위 qubit, 즉 qubit 0에 인코딩합니다. 따라서 이 규칙을 따라 직접 계산할 때는 를 번째 Qubit에, 를 번째 Qubit에 인코딩합니다.
ZFM Circuit 유니터리 연산자는 초기 상태에 다음과 같이 작용합니다:
위 식은 각 Qubit에 대한 연산을 강조하기 위해 텐서곱을 중심으로 재배열한 것입니다. 아래 Qiskit 코드는 ZFM의 구조를 보여주기 위해 Hadamard Gate와 위상 Gate를 명시적으로 사용합니다:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

이제 동일한 데이터 벡터 를 세 번 반복, 인 ZFM Circuit에 인코딩합니다. 이를 위해 Qiskit의 z_feature_map 클래스를 사용하며, 이 전체가 양자 feature map 를 이룹니다. z_feature_map 클래스에서는 기본적으로 파라미터 가 2배로 곱해진 뒤 위상 Gate에 매핑됩니다(). 위에서 직접 계산한 것과 동일한 인코딩을 재현하려면 2로 나누어야 합니다.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

이것은 위에서 직접 계산한 매핑과 다르지만, 파라미터 순서의 일관성에 주목하세요: 는 다시 번째 Qubit에 인코딩되었습니다.
ZFM은 Qiskit의 ZFM 클래스를 통해 사용할 수 있으며, 이 구조를 참고하여 자신만의 feature mapping을 구성할 수도 있습니다.
특성 맵
특성 맵(ZZFM)은 ZFM을 확장한 것으로, 2-Qubit 얽힘 게이트, 구체적으로는 -회전 게이트 를 추가합니다. ZZFM은 ZFM과 달리 고전 컴퓨터에서 일반적으로 계산하기 어려울 것으로 추정됩니다.
는 -상호작용을 구현하며, 일 때 최대로 얽힘 상태를 만듭니다. 는 2-Qubit에 작용하는 일련의 게이트로 분해할 수 있으며, 아래 Qiskit 코드는 RZZ 게이트와 QuantumCircuit 클래스 메서드 decompose를 사용하여 이를 보여줍니다. 여기서는 데이터 벡터 의 단일 특성 를 인코딩합니다.
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

흔히 볼 수 있듯이, .decompose()를 사용하여 구성 게이트를 모두 확인하기 전까지는 단일 게이트 단위로 표현됩니다.
qc.decompose().draw("mpl", scale=1)

데이터는 두 번째 Qubit에서 위상 회전 으로 매핑됩니다. 게이트는 인코딩된 특성 값에 의해 결정되는 얽힘 정도로 두 Qubit을 얽히게 합니다.
완전한 ZZFM Circuit은 ZFM과 마찬가지로 하다마르 게이트와 위상 게이트로 구성되며, 그 뒤에 위에서 설명한 얽힘 연산이 이어집니다. ZZFM Circuit의 단일 반복은 다음과 같습니다:
여기서 는 얽힘 방식에 따라 구성된 ZZ-게이트 레이어를 포함합니다. 여러 얽힘 방식은 아래 코드 블록에 나와 있습니다. 의 구조에는 얽히는 Qubit들의 데이터 특성을 결합하는 함수도 포함되어 있습니다. Qubit 와 에 게이트가 적용된다고 가정해 봅시다. 위상 레이어에서 이 Qubit들은 각각 와 를 인코딩하는 위상 게이트를 갖습니다. 의 인수 는 단순히 이 특성 중 하나가 아니라, 흔히 로 표기되는 함수(방위각과 혼동하지 않도록 주의)로 결정됩니다:
아래 여러 예제에서 이를 확인할 수 있습니다. 다중 반복으로의 확장은 z_feature_map의 경우와 동일합니다:
연산자가 복잡해졌으므로, 먼저 다음 코드를 사용하여 2-Qubit ZZFM과 1회 반복으로 데이터 벡터 을 인코딩해 봅시다:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Qiskit에서는 기본적으로 특성 이 매핑 함수 에 의해 로 함께 매핑됩니다. Qiskit은 사용자가 전처리 단계로서 함수 (또는 게이트로 연결되는 qubit 쌍의 집합 에 대한 )를 사용자 정의할 수 있도록 허용합니다.
4차원 데이터 벡터 로 이동하여 1회 반복의 4-Qubit ZZFM에 매핑하면, 다양한 qubit 쌍에 대한 매핑 를 확인하기 시작할 수 있습니다. 또한 "linear" 얽힘의 의미도 확인할 수 있습니다:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

선형 얽힘 방식에서는 이 Circuit의 인접한(번호 순서대로) qubit 쌍이 얽힙니다. Qiskit에는 circular 및 full을 포함한 다른 내장 얽힘 방식도 있습니다.
파울리 특성 맵
파울리 특성 맵(PFM)은 ZFM과 ZZFM을 임의의 파울리 게이트를 사용하도록 일반화한 것입니다. 파울리 특성 맵은 앞의 두 특성 맵과 매우 유사한 형태를 취합니다. 벡터 의 개 특성을 회 반복 인코딩하면,
PFM에서 는 파울리 전개 유니터리 연산자로 일반화됩니다. 여기서는 지금까지 살펴본 특성 맵의 더 일반화된 형태를 제시합니다:
여기서 는 파울리 연산자로 입니다. 는 단일 qubit 게이트에 작용하는 qubit 집합을 포함하여, 특성 맵에 의해 결정되는 모든 qubit 연결성의 집합입니다. 즉, qubit 0에 위상 게이트가 작용하고 qubit 2와 3에 게이트가 작용하는 특성 맵의 경우, 집합 는 을 포함합니다. 는 해당 집합의 모든 원소를 순회합니다. 이전 특성 맵에서 함수 는 단일 qubit 게이트 또는 2-Qubit 게이트 중 하나에만 관여했습니다. 여기서는 이를 일반적으로 정의합니다:
문서에 대해서는 Qiskit Pauli feature map 클래스 문서)를 참조하세요. ZZFM에서 연산자 는 로 제한됩니다.
위의 유니터리를 이해하는 한 가지 방법은 물리 시스템의 전파자와의 유사성을 통해서입니다. 위의 유니터리는 이징 모델과 유사한 해밀토니안 에 대한 유니터리 발전 연산자 이며, 여기서 시간 매개변수 가 진화를 구동하는 데이터 값으로 대체됩니다. 이 유니터리 연산자의 전개가 PFM Circuit을 구성합니다. 의 얽힘 연결성은 스핀 격자에서의 이징 결합으로 해석될 수 있습니다.
파울리 및 연산자가 이징형 상호작용을 나타내는 예를 살펴보겠습니다. Qiskit은 단일 및 -Qubit 게이트를 선택하여 PFM을 인스턴스화할 수 있는 pauli_feature_map 클래스를 제공하며, 이 예에서는 파울리 문자열 'Y'와 'XX'로 전달합니다. 일반적으로 은 단일 및 2-Qubit 상호작용에 대해 각각 1 또는 2입니다. 얽힘 방식은 "linear"로, Quantum Circuit에서 인접한 Qubit들만 연결됩니다. 이는 양자 컴퓨터 자체의 인접한 Qubit에 해당하지 않을 수 있는데, 이 Quantum Circuit은 추상화 레이어이기 때문입니다.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit은 파울리 특성 맵에서 파울리 회전의 크기를 제어하는 매개변수 를 제공합니다.
의 기본값은 입니다. 예를 들어 구간에서 이 값을 최적화하면 양자 커널을 데이터에 더 잘 맞출 수 있습니다.
Pauli 특성 맵 갤러리
여기서는 두 qubit Circuit에 대한 다양한 Pauli 특성 맵을 시각화하여 가능한 범위를 더 잘 파악합니다.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
위의 예는 물론 Pauli 행렬의 다른 순열 및 반복을 포함하도록 확장할 수 있습니다. 학습자들은 해당 옵션들을 직접 실험해 보세요.
내장 특성 맵 정리
데이터를 양자 Circuit에 인코딩하는 여러 가지 방식을 살펴보았습니다:
- 기저 인코딩 (Basis encoding)
- 진폭 인코딩 (Amplitude encoding)
- 각도 인코딩 (Angle encoding)
- 위상 인코딩 (Phase encoding)
- 밀집 인코딩 (Dense encoding)
이러한 인코딩 방식을 활용해 직접 특성 맵을 구성하는 방법을 살펴보았고, 각도 인코딩과 위상 인코딩을 활용하는 네 가지 내장 특성 맵도 확인했습니다:
- Efficient SU2
- Z 특성 맵
- ZZ 특성 맵
- Pauli 특성 맵
이 내장 특성 맵들은 여러 측면에서 차이가 있습니다:
- 인코딩할 특성 수가 동일할 때의 회로 깊이
- 특성 수가 동일할 때 필요한 qubit 수
- 얽힘(entanglement)의 정도 (이는 당연히 위의 차이들과도 연관됩니다)
아래 코드는 이 네 가지 내장 특성 맵을 특성 집합 인코딩에 적용하고, 결과 Circuit의 두 qubit 깊이를 그래프로 나타냅니다. 두 qubit 오류율이 단일 qubit Gate 오류율보다 훨씬 높기 때문에, 두 qubit Gate의 깊이에 가장 큰 관심을 두는 것이 합리적입니다. 아래 코드에서는 Circuit을 먼저 분해(decompose)한 뒤 count_ops()를 사용하여 모든 Gate의 수를 구합니다. 여기서 관심 대상인 두 qubit Gate는 'cx' Gate입니다:
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
일반적으로 Pauli 및 ZZ 특성 맵은 efficient_su2나 Z 특성 맵보다 Circuit 깊이가 깊고 2-Qubit Gate 수도 많습니다.
Qiskit에 내장된 특성 맵은 범용성이 높기 때문에, 특히 학습 단계에서는 직접 설계할 필요가 없는 경우가 많습니다. 하지만 양자 머신러닝 전문가라면 다음 두 가지 복잡한 과제를 해결해 나가면서 직접 특성 맵을 설계하는 주제로 돌아오게 될 것입니다:
-
현대 하드웨어: 노이즈의 존재와 오류 정정 코드의 큰 오버헤드로 인해 현시점의 응용 프로그램은 하드웨어 효율성 및 2-Qubit Gate 깊이 최소화 등을 고려해야 합니다.
-
문제에 맞는 매핑: 예를 들어
zz_feature_map이 고전적으로 시뮬레이션하기 어렵고 따라서 흥미롭다고 말하는 것과,zz_feature_map이 여러분의 머신러닝 과제나 데이터 집합에 이상적으로 적합하다는 것은 전혀 다른 문제입니다. 다양한 유형의 데이터에 대한 서로 다른 매개변수화 양자 Circuit의 성능은 현재 활발히 연구되고 있는 분야입니다.
마지막으로 하드웨어 효율성에 대해 짚고 넘어가겠습니다.
하드웨어 효율적 특성 매핑
하드웨어 효율적 특성 매핑이란 계산의 노이즈와 오류를 줄이기 위해 실제 양자 컴퓨터의 제약 조건을 고려한 매핑을 말합니다. 근미래 양자 컴퓨터에서 양자 Circuit을 실행할 때 하드웨어 고유의 노이즈를 완화하기 위한 다양한 전략이 있습니다. 하드웨어 효율성을 위한 주요 전략 중 하나는 양자 Circuit의 깊이를 최소화하여 노이즈와 디코히어런스(decoherence)가 계산을 방해할 시간을 줄이는 것입니다. 양자 Circuit의 깊이란 전체 계산을 완료하는 데 필요한 시간 정렬된 Gate 단계의 수입니다 (Circuit 최적화 이후)[5]. 추상적인 논리 Circuit의 깊이는 실제 양자 컴퓨터에 맞게 트랜스파일(transpile)된 후의 깊이보다 훨씬 낮을 수 있음을 기억하세요.
Transpiler는 양자 Circuit을 고수준 추상화에서 실제 양자 컴퓨터에서 실행 가능한 형태로 변환하는 과정으로, 하드웨어 제약 조건을 고려합니다. 양자 컴퓨터에는 기본 단일 qubit 및 두 qubit Gate 집합이 있습니다. 즉, Qiskit 코드의 모든 Gate는 하드웨어 기본 Gate 집합으로 트랜스파일되어야 합니다. 예를 들어, 2023년에 완성된 Heron r1 프로세서를 탑재한 QPU인 ibm_torino의 기본(basis) Gate는 {CZ, ID, RZ, SX, X}입니다. 이는 각각 두 qubit 제어-Z Gate와, 항등(identity), -회전, NOT의 제곱근, NOT이라 불리는 단일 qubit Gate로 구성되어 범용 게이트 집합을 이룹니다. 다중 qubit Gate를 동등한 서브 Circuit으로 구현할 때는 물리적 두 qubit Gate와 하드웨어에서 사용 가능한 기타 단일 qubit Gate가 필요합니다. 또한 물리적으로 연결되어 있지 않은 두 qubit 쌍에 두 qubit Gate를 수행하려면, qubit 상태를 이동시켜 결합을 가능하게 하기 위해 SWAP Gate가 추가되어 Circuit이 불가피하게 길어집니다. 0부터 최대 3까지 설정할 수 있는 optimization 인수를 사용할 수 있습니다. 더 많은 제어와 커스터마이징을 위해서는 Qiskit Pass Manager를 통해 Transpiler 파이프라인을 관리할 수 있습니다. 트랜스파일에 대한 자세한 내용은 Qiskit Transpiler 문서를 참고하세요.
Havlicek 외 2019 [2]에서 저자들이 하드웨어 효율성을 달성하는 방법 중 하나는 2차 확장(second-order expansion)인 특성 맵을 사용하는 것입니다 (위의 " 특성 맵" 섹션 참고). 차 확장은 -Qubit Gate를 가집니다. IBM® 양자 컴퓨터는 인 -Qubit Gate를 기본으로 지원하지 않으므로, 이를 구현하려면 하드웨어에서 사용 가능한 두 qubit CNOT Gate로 분해해야 합니다. 저자들이 깊이를 최소화하는 두 번째 방법은 하드웨어 아키텍처 결합에 직접 매핑되는 결합 토폴로지를 선택하는 것입니다. 이들이 수행하는 추가 최적화로는 성능이 우수하고 적절히 연결된 하드웨어 서브 Circuit을 타겟으로 하는 것도 있습니다. 추가로 고려할 사항으로는 특성 맵 반복 횟수(reps) 최소화, 모든 Qubit을 얽히게 하는 "full" 방식 대신 사용자 정의 저깊이(low-depth) 또는 "linear" 얽힘 방식 선택 등이 있습니다.

위 그래픽은 물리적 Qubit과 하드웨어 결합을 각각 나타내는 노드와 엣지로 구성된 네트워크를 보여줍니다. 가능한 모든 두 qubit CZ 결합 Gate를 포함한 ibm_torino의 결합 맵과 성능이 나타나 있습니다. Qubit은 마이크로초(μs) 단위의 T1 이완 시간 기준으로 색상으로 구분되며, T1 시간이 길수록 더 좋고 밝은 색으로 표시됩니다. 결합 엣지는 CZ 오류를 기준으로 색상으로 구분되며, 어두운 색일수록 더 좋습니다. 하드웨어 사양 정보는 하드웨어 Backend 구성 스키마 IBMQBackend.configuration()을 통해 확인할 수 있습니다.
참고 문헌
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()